
What does it actually mean when we say that Google uses Machine Learning algorithms? In our latest Unwrapping the Secrets of SEO, guest contributor Olaf Kopp explains what exactly this refers to and where neural networks are applied in Google Search. Webmasters and SEOs take heed: you’re key to helping provide Google’s algorithms with training data.

This article is the last in my series on Machine Learning. The previous Unwrapping posts can be found here:
Part 1: How Google Interprets Search Queries
Part 2: It’s All Semantic For Google Search
Part 3: How Does Google’s Knowledge Graph Work?

As discussed in the article, The Semantic Web (German), systems based on the innovations of Web 2.0, which make information identifiable, categorizable, measurable and sortable according to context, are the only way to get on top of the flood of information and data.
But pure semantics is not enough here because it depends on statistical methods. Semantic systems require the predefinition of classes and labels in order to classify data. Moreover, it is difficult to identify and create new entities without manual help. For a long time, this could only be done manually or with reference to manually maintained databases like Wikipedia or Wikidata, which prevents scalability.
Because of this, digital gatekeepers need increasingly reliable autonomous algorithms to manage these tasks. In the future, self-learning algorithms based on Artificial Intelligence and Machine Learning methods will play an ever-more important role. This is the only way of guaranteeing that outputs/results comply with expectations while also retaining scalability.
Rise of the Machines
Before I go into the role of Machine Learning in Google Search today, it is important to understand how Machine Learning works. In my explanation, I will only scratch the surface of the topic because I’m not a trained mathematician or computer scientist and I lack more detailed knowledge of how such algorithms are constructed.
Machine Learning can be considered part of the field of Artificial Intelligence. The term “intelligence” does not quite apply in relation to Machine Learning because it is not so much about intelligence, but more about patterns that machines or computers can recognize, and about accuracy.
Machine Learning deals with the automated development of algorithms based on empirical data or training data. As a result, the focus is on the optimization of results or improving predictions based on learning processes.
Google’s application of Machine Learning
These algorithms are also often used at Google for the classification and clustering of information, and for making predictions on this basis. According to its own statement, Google relies on Supervised Machine Learning, which means that at different points in the Machine Learning process, humans pre-classify and evaluate results.
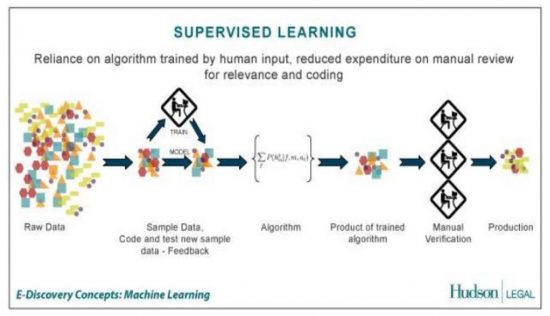
According to their own statements, Google uses deep neural networks with at least five layers, which is then referred to as Deep Learning. Using neural networks of this depth makes it possible to automatically and independently create new model groups, which again greatly increases the scalability
Machine Learning can be used wherever Google has to assign labels or comments to data, and/or has to run clustering, which would be too laborious manually. Up to now, the use of Machine Learning in Google Search has only been confirmed by RankBrain. However, I can also imagine Machine Learning already being used for the clustering of documents in the indexing process. If you would like to know more about Google, AI, and Machine Learning, I recommend my article, Significance of Machine Learning, AI & RankBrain for SEO & Google (German), with interesting opinions from respected colleagues like Markus Hövener, Kai Spriestersbach, Marcus Tober and Sebastian Erlhofer.
Google Also Learns Thanks to the Help of Webmasters and SEOs
The development of a semantic database in the form of the Knowledge Graph, but also generally with the identification of entities, depends a lot upon the help of external persons, such as webmasters and Wikipedia editors. In general, however, Google’ long-term aim is to be able to independently retrieve data that can interpreted, so that the Knowledge Graph project does not stall.
This is also apparent in the Knowledge Vault project. The Knowledge Vault was unveiled by Google in 2014 as an inactive development project that was supposed to make use of web crawling, Machine Learning, structured and unstructured data, to build up the largest knowledge database in the world. In addition, there is to date no information on whether and how far Google already actively uses this database. But I hypothesize that the Knowledge Graph already obtains information from the Knowledge Vault. More on this can be found in the article, Google “Knowledge Vault” To Power Future Of Search.
I assume that Google has a great interest in recognizing information for the Knowledge Graph without the assistance of external people – and ideally automated. There are already some clues here that Google repeatedly supplies human-verified training data for its own Machine Learning systems in order to identify and classify entities more quickly.
For example, Google also double-checks the information for the medical boxes of professors and doctors at Harvard and the Mayo Clinic before they are published in Knowledge Graph boxes. This manual proofing could also be used with Supervised Machine Learning for the improvement of algorithms. Google could also provide the self-learning algorithms with feedback from the search evaluators (Quality Rater), as these could be another source of valuable training data.
Structured Data as Human-Verified Training Data for Google’s Algorithm
Another example of how Google is increasingly trying to operate independently from webmasters is the rel-authorship markup. To my mind, this markup had only one purpose for Google: the identification of patterns that are used for particular types of entities. The information and mark-ups were created or populated by people (primarily SEOs and webmasters) and were therefore verified training data that Google could feed into their Machine Learning algorithms to create model groups for authors according to these patterns.
Thus, it is not surprising that Google eventually stopped pursuing the projects rel-authorship or Freebase. Freebase was initially filled with data that people added according to a basic semantic framework. This gave Google both a semantic playground and enough human-verified training data for the Machine Learning algorithm. But Freebase was only a short-term means to an end.
How Structured Data became Obsolete for Google Shopping
In my opinion, this will also happen in the next few years with a large proportion of all structured data, as soon as Google no longer needs it. This is also just human-verified training data, which could become obsolete at some point.
The fact that structured data could be only a waypoint and that Google would ideally like to dispense with this input in the form of tagging by webmasters and SEOs, is also demonstrated by the latest developments in Google AdWords or Google Shopping.
AdWords advertisers who ran a shopping feed in the past few months received a mail with the following text:
“As of October 30, 2017, the most up-to-date information on pricing and availability of your articles will be determined based on annotations for structured data or additional information (if no structured data is available). Therefore, your customers benefit from increased usability of Google Shopping.”
If you sometimes look at Google Shopping’s help, you will find the following wording regarding the shopping feeds:
“Advanced extractors are able to find price and availability information on a product’s landing page. They use a combination of statistical models and machine learning to detect and extract product data from your website independent structured data markup.” Source: https://support.google.com/merchants/answer/3246284?hl=en
This shows how, over the past few years, Google has learned via Machine Learning to interpret content automatically and independent of structured data, and to assign the content a class. Through this process, the shop-providers were an important help, who spent the last years obediently tagging their shopping feeds with structured data. Verified training data for Google Shopping’s hungry Machine Learning algorithm.
This goal is clearly stated by Google, straight from Gary Illyes:
“I want to live in a world where schema is not that important, but currently, we need it. If a team at Google recommends it, you probably should make use of it, as schema helps us understand the content on the page, and it is used in certain search features (but not in rankings algorithms)… Google should have algorithms that can figure out things without needing schema …” Source: https://searchengineland.com/gary-illyes-ask-anything-smx-east-285706
In addition, I have to mention that in the same quotation Gary denies whether schema.org data is being used as training data. This contradicts my assumption.
“No, it’s being used for rich snippets.”
Conclusion: Machine Learning Steps towards Semantic Understanding
- Google wanted to introduce semantic search with the Knowledge Graph and the Hummingbird algorithm. Today, however, it is clear that the goal of a semantic understanding has long failed to develop due to a lack of scalability.
- Given the enormous volume of search queries and documents, the semantic classification of information, documents and search queries is only practical in combination with Machine Learning systems. Otherwise the sacrifices in performance are too great. Also, this has been made possible thanks to the energetic help of SEOs and Webmasters, who tag information manually themselves.
- The ability to make predictions regarding what a user would like when they enter a previously unknown search term in the search bar is only possible through Machine Learning.