Almost every search term is an implicit or explicit question. With voice search and mobile devices, it is even more important for Google to be able to identify search queries and the user intent or meaning behind them. This helps the search engine provide search results that precisely match the user’s request. In our latest Unwrapping the Secrets of SEO, guest expert Olaf Kopp, co-founder, head of SEO and Chief Business Development Officer (CBDO) at Aufgesang Inbound marketing GmbH, examines semantics and machine learning at Google.

What’s it all mean?

In 2009, Ori Allon, then technical lead of the Google Search Quality Team, said in an interview with IDG:
“We’re working really hard at search quality to have a better understanding of the context of the query, of what is the query. The query isn’t the sum of all the terms. The query has a meaning behind it. For simple queries like ‘Britney Spears’ and ‘Barack Obama’ it’s pretty easy for us to rank the pages. But when the query is ‘What medication should I take after my eye surgery?’, that’s much harder. We need to understand the meaning…”
Ultimately, Google wants to identify the user, or search, intent.
How Google identifies search intent
To do this, Google has to understand the context. When talking about context, we have to differentiate between search query context like the relationships between terms, user context like the location and (search) historical, and topical context. Some forms of context are dynamic and can change over time. By considering all available forms of context, an individual and solid understanding of user intent can be extrapolated for each search query.
Google therefore has to answer the following questions:
- Where is the user?
- Which device is the user searching with?
- What has the user been interested in in the past?
- How are the terms used related to one another?
- Which entities are included in the search request?
- In which topical context are the terms used?
- Google can quickly answer the first two questions using client-information, GPS data and IP addresses. The third question can be answered using search history, clicks in the SERPs and general online behavior.
- The last three questions, which relate to the actual meaning of the search query, cannot be answered as easily.
Enter RankBrain
Google’s introduction of RankBrain was a huge step towards improved scaling and performance.
In order for Google to be able to recognize the meanings of search terms, a kind of semantic understanding has to be imitated using statistical methods. This requires the classification of search terms using comments or annotations and the mapping of terms which are not yet known to relevant topics. Due to the enormous number of search terms which are entered into Google every day, this cannot possibly take place manually. To enable scalability, it has to take place using cluster analyses and automatic clustering.
Google has been able to do this since 2015, when it introduced Machine Learning in the form of RankBrain. This helped Google join the dots between scalability and the reconstructed semantic understanding of search queries.
Methods for interpreting search queries
Google uses so-called vector space analyses to interpret search queries. These convert the search query into a vector, and draw the relationships to other terms within the vector space. By comparing relationship patterns, the search intent or meaning can be identified, even if the specific search query has not been previously analyzed.
In this regard, user signals like the click-through rate on the individual search result seem to play a particularly important role. In two scientific projects that Google employees were involved in, I discovered interesting information regarding how an algorithm addressing this could work.
In Learning from User Interactions in Personal Search via Attribute Parameterization, it is explained how Google may be able to use an analysis of user behavior and individual documents to create semantic attribute relationships between search queries and the documents clicked on – and even to support a self-learning ranking algorithm:
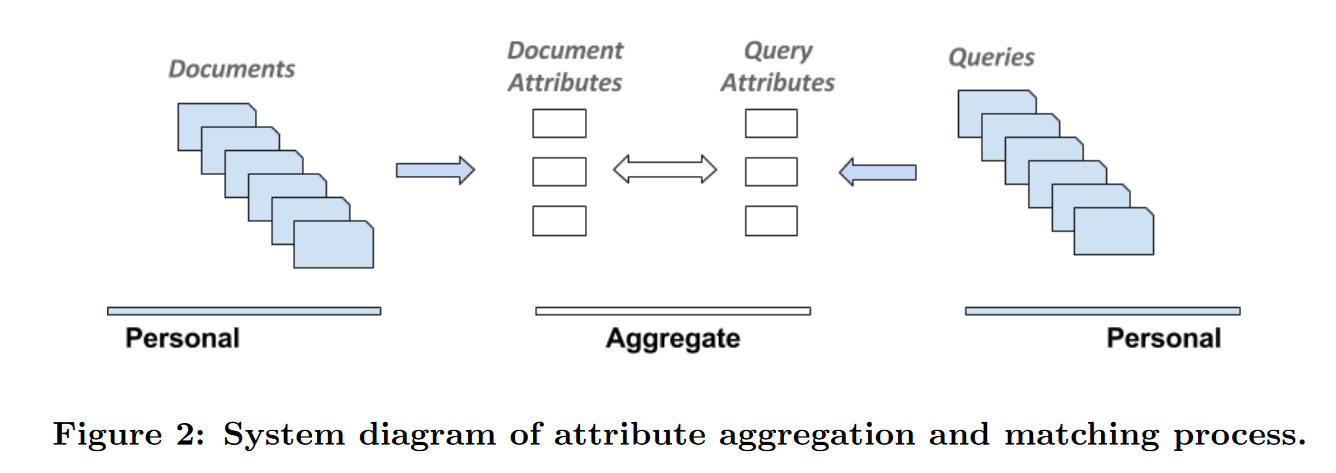
“The case in private search is different. Users usually do not share documents (e.g., emails or personal files), and therefore directly aggregating interaction history across users becomes infeasible. To address this problem, instead of directly learning from user behavior for a given [query, doc] pair like in web search, we instead choose to represent documents and queries using semantically coherent attributes that are in some way indicative of their content.
This approach is schematically described in Figure 2. Both documents and queries are projected into an aggregated attribute space, and the matching is done through that intermediate representation, rather than directly. Since we assume that the attributes are semantically meaningful, we expect that similar personal documents and queries will share many of the same aggregate attributes, making the attribute level matches a useful feature in a learning-to-rank model.”
Another scientific paper from Google with the title “Improving semantic topic clustering for search queries with word co-occurrence and bipartite graph co-clustering” provides several interesting insights into how Google now probably categorizes search queries into different topic clusters.
In this document, two methods are presented that Google uses to establish content for search queries. So-called “lift scores” play a central role in the first, entitled “Word Co-occurrence Clustering”:
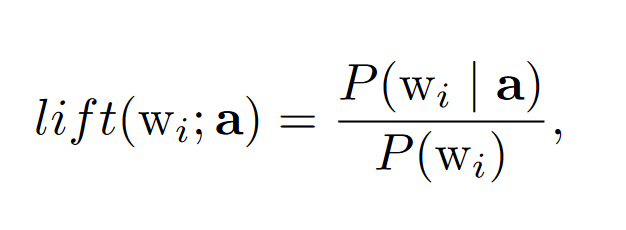
In this formula, “wi” stands for all terms that are closely related to the word’s root, like misspellings, plurals, singulars and synonyms. “a” can be any user interaction like the search for a particular search term or visiting a particular page. If the lift score is, for example, 5, then the probability that “wi” is being searched for is five times higher than the general likelihood of “wi” being searched for.
“A large lift score helps us to construct topics around meaningful rather than uninteresting words. In practice the probabilities can be estimated using word frequency in Google search history within a recent time window.”
This makes it possible to assign terms to certain entities like “Mercedes” and/or – if there is a search for replacement car parts – to the topical context cluster “car.” The context cluster or entity can then also have terms assigned to it that often appear as co-occurrences with the search term. This makes it possible to quickly create a search term wordcloud for a certain topic. The size of the lift score determines the closeness to the topic:
“We use lift score to rank the words by importance and then threshold it to obtain a set of words highly associated with the context.”
This method is particularly useful when “wi” is already known, like with searches for brands or categories that are already known. If “wi” cannot be clearly defined, because the search terms for the same topic are too varied, then Google could use a second method: weighted bigraph clustering.
This method is based on two assumptions:
- Users with the same intent phrase their search queries differently. Search engines still display the same search results.
- For any given search query, similar URLs are displayed amongst the top search results.
Applying this method, the search terms are compared with the top-ranking URLs and query-URL pairs are created whose relationship is also weighted according to users’ click-through rates and page impressions. This makes it possible to recognize similarities between search terms that do not contain the same lexical root, and thereby create semantic clusters.
The role of entities in interpreting search queries
Google wants to find out what the entity is that a question is referring to. By looking at the entities in a search term and the relational context between entities, Google can identify the sought entity.
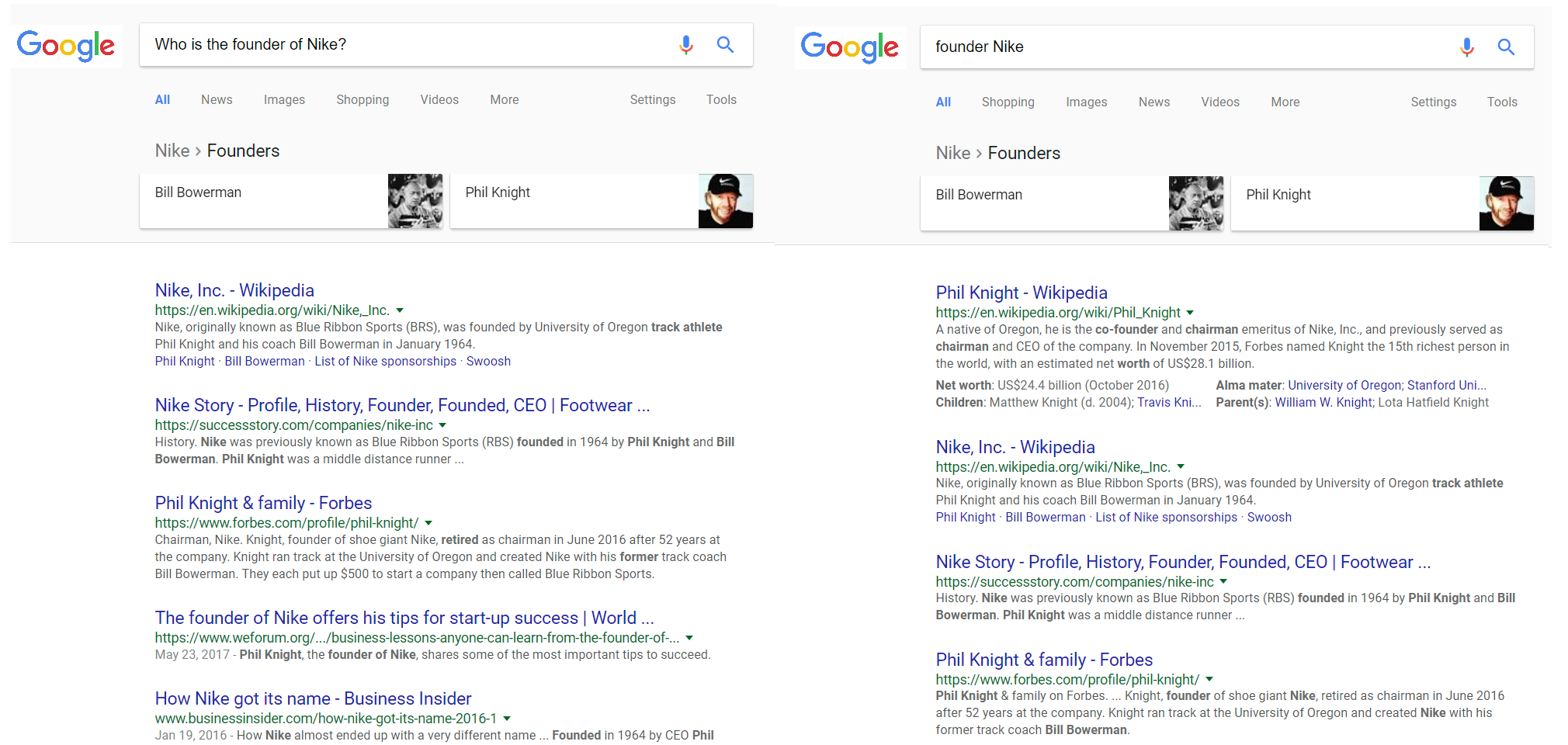
Even if the results do differ slightly, Google recognizes that the entities, “Bill Bowerman” and “Phil Knight,” are being searched for, even though the names do not appear in the search query. And it makes no difference whether I ask an implicit question like, “founder Nike” or an explicit question. The entity, “Nike,” and the relational context, “founder,” are sufficient.
This capability is often erroneously attributed to RankBrain and/or Google’s Machine Learning technologies. However, it actually has its origins in the functionality of Hummingbird, together with the Knowledge Graph. Ergo: Google was able to do this before RankBrain ever showed up.
As early as 2009, Google introduced the first semantic technologies for interpreting search terms with its “related searches.” The inventor of this technology, Ori Allon, already prepared Google’s users for the underlying technology having a wider-reaching impact on rankings. The patent for the technology developed by Allon can be found here.
The patent primarily deals with the interpretation of search queries and its fine-tuning. This means that it is likely this that RankBrain would later build on with its Machine-Leaning technologies. Since RankBrain (if not earlier), Google has been able to conduct a scalable semantic interpretation of search queries using Machine Learning.
According to the patent, the fine-tuning of a search query relates to particular entities that frequently appear together in documents ranking for the original search query or for synonyms.
The problem pre-RankBrain was the lack of scalability when looking to identify entities and store them in the Knowledge Graph. The Knowledge Graph is mainly based on information from Wikidata, which is verified by Wikipedia entities – meaning it is a manually curated and therefore static and non-scalable system.
“Wikipedia is often used as a benchmark for entity mapping systems. As described in Subsection 3.5 this leads to sufficiently good results, and we argue it would be surprising if further effort in this area would lead to reasonable gains.”
Source: From Freebase to Wikidata – The Great Migration
Google Gets Good (or Great?)
It can be safely assumed that Google has been working on the development of a search engine that includes semantic influences to better understand the meaning of search queries and documents since at least 2007.
As of today, with semantic structures like the Knowledge Graph and with Machine Learning, Google seems to be very close to the goal stated by former VP, Marissa May, of moving away from a purely keyword-based search engine to a concept- or context-based search engine.
“Right now, Google is really good with keywords and that’s a limitation we think the search engine should be able to overcome with time. People should be able to ask questions and we should understand their meaning, or they should be able to talk about things at a conceptual level. We see a lot of concept-based questions — not about what words will appear on the page but more like ‘what is this about?’”
Source: Google wants your Phonemes – Infoworld
And, really, it’s high time Google reached this goal – if you consider that Voice Search is on the march worldwide and that search queries are becoming more and more complex.