
The Knowledge Graph is Google’s semantic database. This is where entities are placed in relation to one another, assigned attributes and set in a thematic context or an ontology. But what is an entity? And how does the Knowledge Graph actually work? Find the answers to these questions in our latest Unwrapping the Secrets of SEO, the last in part three in Olaf Kopp’s series looking at Google’s semantics and machine learning.

If you need to catch up, you can read part 1 here: How Google Interprets Search Queries. And part 2 can be found here: It’s All Semantic For Google Search.

Semantics = Entities plus Ontologies
The most important elements of a fundamental semantic structure and entities and ontologies. In semantics, an entity is unambiguously described by an identifier and particularly characteristics (attributes or properties). Whilst the identifier (URI), which usually consists of a sequence of numbers, is used by machines to identify the entity, humans recognize entities according to their characteristics.

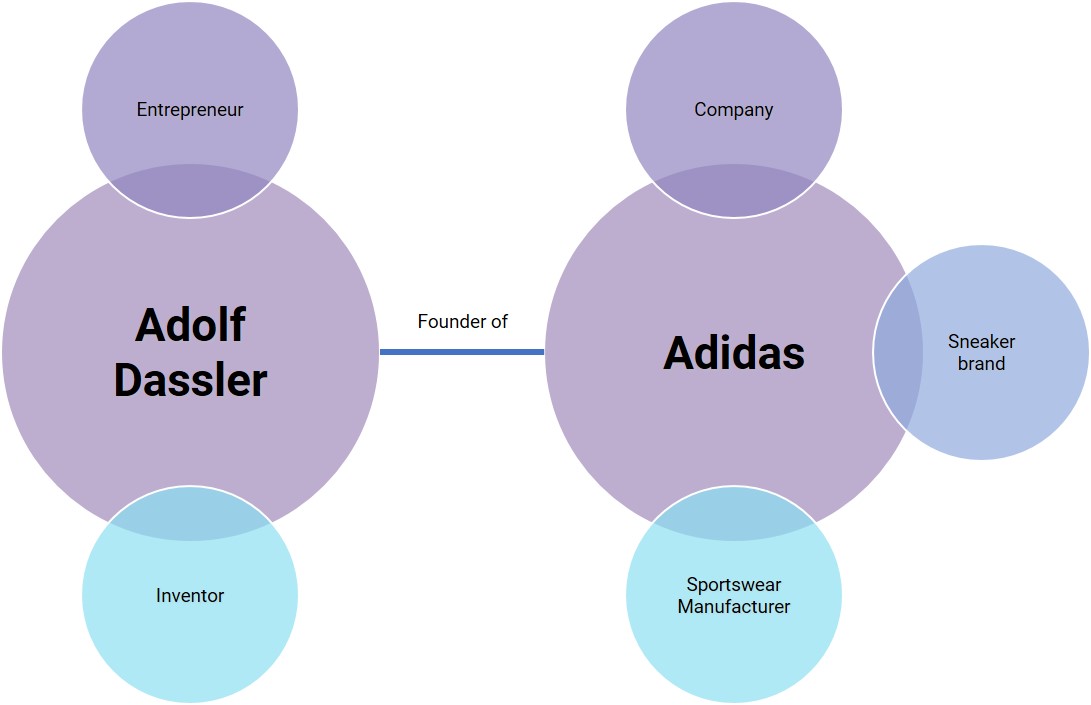
Entities are always part of an ontology. Ontologies describe the environment that entities exist within. This can be demonstrated using the example of the following entities: Adolf Dassler, Adidas, Reebok and Foot Locker. Adolf Dassler is an entrepreneur and inventor, and is the founder of the sportswear manufacturer Adidas:
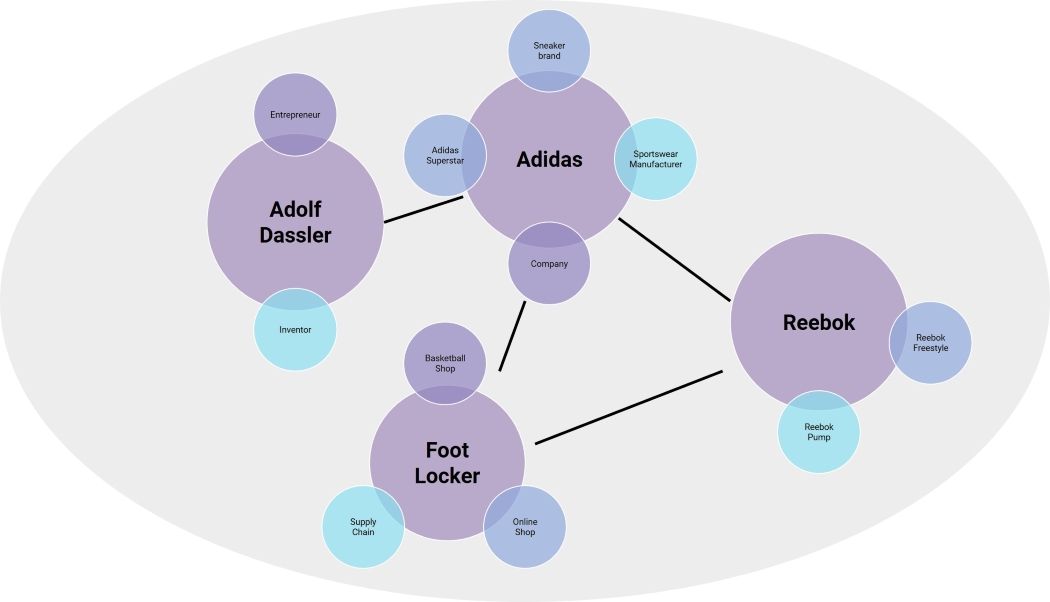
Reebok is a subsidiary of Adidas. The sportswear retailer, Foot Locker, is a customer of both Adidas and Reebok, and sells products like the Adidas Superstar or the Reebok Freestyle:
To represent semantic structures, it is helpful to make use of graph theory. This theory is the basis for Google’s Knowledge Graph and Facebook Graph Search.
Graphs consist of nodes and edges. When looking at semantics, the nodes represent the entities and the edges represent the relationships between entities. These relationships can also be assigned values like a “relational context”. In the example above, the relational context between Adolf Dassler and Adidas is “founder”.
A graph contains all relevant entities, whatever their ontology. In addition to showing the existence of a relationship between entities, edges can also be used to indicate the values of these relationships e.g. through their length and thickness. A particularly thick connecting edge could represent an intense relationship between the two entities. The relationship distance, shown by the length of the edge, can also be used to represent how closely the two entities are related. It is also possible to create a link to vector spaces including Euclidian distances. This means that a graph structure can be created from statistical methods like vector space analyses.
What does Google consider an entity?
Entities are particularly important for Information Retrieval Systems, because they make it possible to infer further additional information regarding the context of a search query, a sentence or a text.
The unambiguous identification of entities is important for Google as it helps with a number of tasks:
- Interpretation of search queries
- Provides clarity when analyzing terms with multiple meanings
- Identifying the relationships between entities and their meaning in terms of ontologies or topics
- Interpretation of documents
- Identifying relevant entities in a thematic context
Theoretically, there is an extensive list of possible types of entity, including:
- Books
- Educational Institutes
- Events
- State Institutions
- Companies
- Films
- TV Series
- Bands
- Organizations
- People
- Places
- ….
A look at the types of entity listed on schema.org gives us a complete overview of everything that can be evaluated as an entity. It is not entirely straightforward to assess what Google actually categorizes as an entity and what not. In a patent description that Google refers to in one of its own patents, we find the following definition:
A named entity is a group of one or more words (a text element) that identifies an entity by name. For example, named entities may include persons (such as a person’s given name or role), organizations (such as the name of a corporation, institution, association, government or private organization), places(locations) (such as a country, state, town, geographic region, a named building, or the like), artifacts (such as names of consumer products, such as cars), temporal expressions, such as specific dates, events (which may be past, present, or future events, such as World War II; The 2012 Olympic Games), and monetary expressions. Quelle: https://www.google.com/patents/US20100082331
It would appear that Google displays relevant entities in the Knowledge Graph boxes to the right of the search results. For this reason, I like to call them “Entity Boxes”. Things that appear above the organic search results, in a direct answer box or as a featured snippet, tend to be concepts or topics. The carousels at the very top of the page show things like events, films and TV shows.
If we take a closer look at the Entity Boxes, then we see that:
- People
- Companies
- Animals
- Buildings
- Towns/places
play an important role as entities.
When talking about entities, it is important to differentiate between Entity Boxes according to the information sources they refer to: to Google My Business (local companies), to Google+ (people) or to the Knowledge Graph (companies, people, animals, towns/places). The information in the Entity Boxes that refers to My Business or Google+ can largely be created and controlled by the company or individual themselves.
Where does Google get the information for its Knowledge Graph from?
Google draws its information on entities and their relationships to one another from the following sources:
- CIA World Factbook, Wikipedia/Wikidata (formerly Freebase)
- Google+ and/or Google My Business
- Structured data (schema.org)
- Web crawling
- Knowledge Vault
- Licensed data
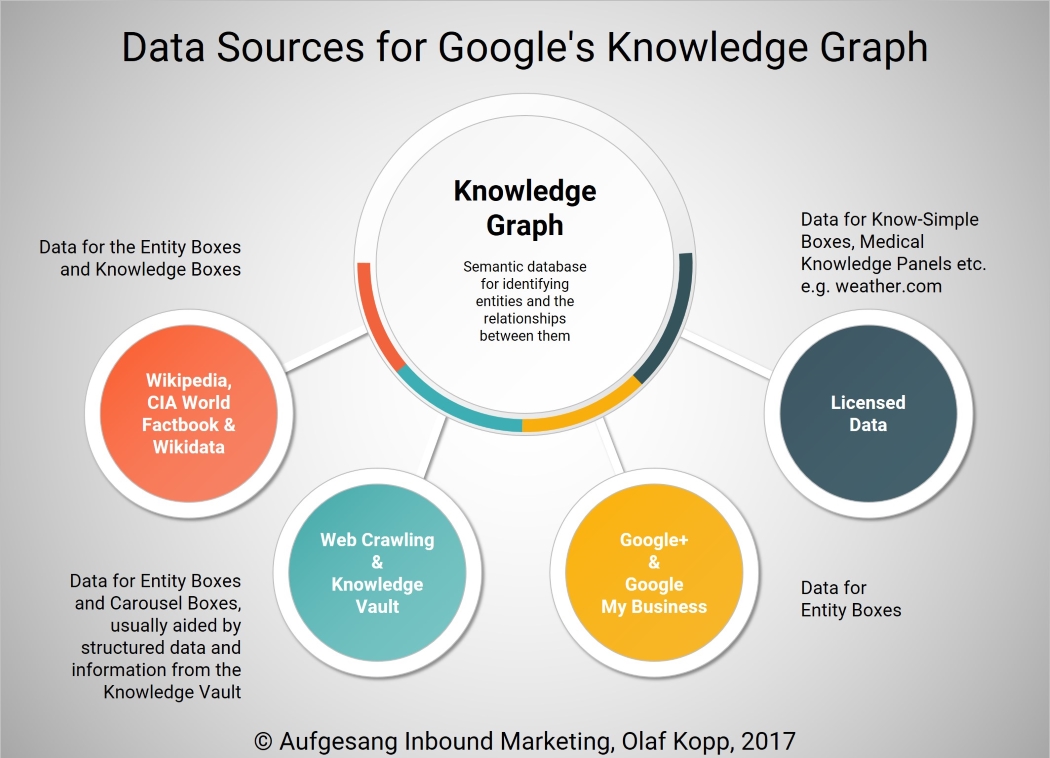
Data Sources for Google’s Knowledge Graph, © Aufgesang Inbound Marketing 2017
The Knowledge Graph is Google’s semantic database. This is where entities are placed in relation to one another and placed in a thematic context or an ontology. Google’s development of the Knowledge Graph seems to be closely linked to the purchase of the semantic knowledge database, Freebase. I like to view Freebase as a kind of experimental playground that Google was able to use for its first foray into dealing with structured data.
Google introduced the Knowledge Graph in 2012. Initially, it was populated with data from Freebase and Wikipedia. The open-source project, Freebase, ended in 2014 and was transformed into what is now the closed project, Wikidata. For the display of an Entity Box, Google checks to see whether there is a data entry in Wikidata or a page on Wikipedia.
In one scientific project that a Google employee was involved in, entities are equated to Wikipedia entries.
“An entity (or concept, topic) is a Wikipedia article which is uniquely identified by its page-ID.”
Wikipedia articles play a pivotal role as an information source for many Knowledge Graph boxes. Together with Wikidata entries, Google uses them as proof of an entity’s relevance. No Wikipedia article and no Wikidata, no Entity Box. Wikipedia’s importance in the identification of entities and their thematic context is investigated in the scientific paper Using Encyclopedic Knowledge for Named Entity Disambiguation.
One way Google can identify relationships between entities could be by analyzing annotations and links within Wikipedia.
“An annotation is the linking of a mention to an entity. A tag is the annotation of a text with an entity which captures a topic (explicitly mentioned) in the input text.”
The development of a semantic understanding for the interpretation of search queries and documents is closely connected to the ability to identify entities and the relationships between them, and the ability to place them in a context or ontology. This is possible with the help of verified data sources like Wikipedia. However, the huge volume of search queries and documents that are created every day makes this process somewhat unsuitable. This is one of the reasons why Google has, for several years now, been driving the development of self-learning algorithms and machine learning.