
Milestones such as the Knowledge Graph, Hummingbird and RankBrain have helped bring Google a few steps closer to becoming a perfect search engine. Statistics, semantic theories and structures, and machine learning all play an important role. In the latest Unwrapping the Secrets of SEO, guest author Olaf Kopp examines aspects of semantics and machine learning in Google search.

In the last installment of Unwrapping the Secrets of SEO, I outlined my view on how Google interprets search queries and the user intent behind them. Now it’s time to take a look at how Google does such a good job at improving search accuracy.
Semantic Search or Statistical Information Retrieval?
I have had many a heated argument (civilized debate?) with fellow SEO Jens Fauldrath over whether Google really is a semantic search engine.
The results that Google presents its users certainly make it look like the search engine giant has a highly developed semantic understanding regarding search queries and documents. However, much of what leads to this appearance is based on statistical methods, and not on any genuine semantic understanding. But due to semantic structures, in combination with statistics and machine learning, Google is now able to get close to semantic understanding.
“For instance, we find that useful semantic relationships can be automatically learned from the statistics of search queries and the corresponding results, or from the accumulated evidence of Web-based text patterns and formatted tables, in both cases without needing any manually annotated data.” Source: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
How Word2Vec Works
To demonstrate this more clearly, I will briefly enter the work of statistical text analysis. Google uses vector space analyses for the evaluation of relevance and the identification of relationships. A vector space consists of individual data points that can be linked via vectors in the vector space. The angle between the vectors tells us about similarities and/or relationships between data points. The larger the angle, the less similarity there is. The smaller the angle, the larger the similarity. For the analysis of the main components, for example, a vector is created in the vector space from the search query and all available relevant documents. For this so-called “word embedding” process, Google uses Word2vec.
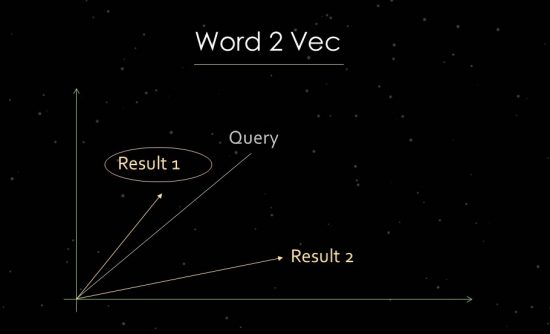
Using the proximity of data points to one another makes it possible to show the semantic relationships between them. Typically, vectors are created for search queries and documents that can be placed in relation to one another. Another usage is creating vectors from a document and the terms within it in order to identify its concept or topic. It would also be possible to form vectors from entities like people, brands, companies or topics.
In order to make use of vector space analyses, documents first need to be indexed and mapped to concepts or topic areas that then make up the relevant topical corpus. A process for carrying out this step is Latent Semantic Indexing (LSI), which makes it possible to create vector spaces that provide the best results in terms of precision and recall. Using this method, it is also possible to carry out semantic classification or clustering of terms related to a topic.
How Search Queries Can be Automatically Classified
In the past, the main problem was the lack of scalability as search queries had to be manually classified. These are former Google VP Marissa Mayer’s words on the subject from a 2009 interview:
“When people talk about semantic search and the semantic Web, they usually mean something that is very manual, with maps of various associations between words and things like that. We think you can get to a much better level of understanding through pattern-matching data, building large-scale systems. That’s how the brain works. That’s why you have all these fuzzy connections, because the brain is constantly processing lots and lots of data all the time… The problem is that language changes. Web pages change. How people express themselves changes. And all those things matter in terms of how well semantic search applies. That’s why it’s better to have an approach that’s based on machine learning and that changes, iterates and responds to the data. That’s a more robust approach. That’s not to say that semantic search has no part in search. It’s just that for us, we really prefer to focus on things that can scale. If we could come up with a semantic search solution that could scale, we would be very excited about that. For now, what we’re seeing is that a lot of our methods approximate the intelligence of semantic search but do it through other means.” Source: http://www.pcworld.com/article/181874/article.html
Much of what we call semantic understanding when we talk about Google identifying the meaning of a search query or document is built on statistical methods like vector space analyses or methods of statistical text analysis like TF-IDF. Strictly speaking, this is therefore not based on genuine semantics. But the results do get very close to semantic understanding. The increased application of machine learning – and the more detailed analyses this enables – makes the semantic interpretation of search queries and documents much easier.
Semantic Understanding as one of Google’s Goals
One of Google’s most important goals is achieving semantic understanding regarding search terms and indexed documents in order to display more relevant search results. A semantic understanding exists when a (search) query and the terms contained within it can be unambiguously understood. Unambiguous interpretation is often made difficult by queries including terms with multiple meanings, terms unknown by the system, unclear phrasing, individual understanding etc.
To aid understanding, analysis is conducted of the words used, their order, and the contexts of their topic, time and location. Machine learning and/or RankBrain enable Google to use cluster analyses to automatically create new classes and assign search queries to them. This not only establishes a high level of detail, but also creates scalability and increases performance. The creation of new vector spaces for vector space analyses is also made possible.
In this way, statistics combine with machine learning to give an increasingly semantic interpretation that comes very close to a semantic understanding of search queries and documents. Google wants to be able to recreate a truly semantic search with the help of statistical methods and machine learning. Furthermore, a central element of the modern Google search engine, the Knowledge Graph, is also based on semantic structures.
In part three of this article series on Google’s semantics and machine learning, Olaf Kopp will look at the Foundations of Semantics: Graphs, Entities and Ontologies.