
Von Sitemaps über das Staging bis hin zum Hreflang gibt es viele potenzielle Stolperfallen im technischen SEO: Im ersten Teil unserer Webinar-Reihe „Springen Sie auf das nächste SEO Level!“ haben euch Thomas Gruhle, Gründer und CEO der Online-Marketing-Agentur LEAP, und ich gezeigt, was ihr tun müsst, um diese SEO-Fehlerquellen zu vermeiden und eure Website technisch perfekt aufzustellen. In diesem Beitrag werde ich gemeinsam mit Thomas eure Fragen zum Thema beantworten.
- Video: 10 technische Fehler, die das Ranking beeinflussen
- SEO-Stolperfalle #1: Canonicals
- SEO-Stolperfalle #2: Paginierung
- SEO-Stolperfalle #3: Mehrsprachigkeit
- SEO-Stolperfalle #4: Noindex, Nofollow & Robots.txt
- SEO-Stolperfalle #5: Sitemaps
- SEO-Stolperfalle #6: PDFs
- SEO-Stolperfalle #7: Bilder
- SEO-Stolperfalle #8: Redirects
- SEO-Stolperfalle #9: Relaunch & Redesign
- SEO-Stolperfalle #10: 4xx Fehler
- Weitere Fragen zu den SEO-Stolperfallen
Verpasst nicht die weiteren Webinare mit Searchmetrics & LEAP! Am 20 März geht’s um den Website-Relaunch – und was dabei schief gehen kann, was ihr im Hinblick auf SEO unbedingt beachten solltet und wie ihr nach dem Relaunch besser darsteht als zuvor. Und am 17. April 2019 geht’s um SEO für Bing. Ihr lernt, wie die Bing Webmaster Tools funktionieren, was anders ist als bei Google und wie ihr Bing am besten nutzen können.
Video: 10 technische Fehler, die das Ranking beeinflussen
Wer beim Webinar nicht mit dabei war, kann sich die Video-Aufzeichnung zunächst anschauen, bei der wir eure Fragen zu den 10 wichtigsten technischen SEO-Stolperfallen beantworten:
Im Laufe des Webinars gab es zahlreiche weitere Fragen von euch. Nachfolgend beantworten wir weitere Fragen zu den 10 SEO-Stolperfallen, die wir nicht im Webinar klären konnten. Los geht’s mit euren Fragen und unseren Antworten zu den 10 wichtigsten technischen SEO-Problemen:
SEO-Stolperfalle #1: Canonicals
Ist das Setzen von selbstreferenziellen Canonicals von beispiel.de/beispiel auf beispiel.de/de/beispiel korrekt?
Thomas: Das o.g. Beispiel ist kein selbstreferentieller Canonical-Tag, sondern ein Verweis von A nach B. Ein selbstreferentieller Canonical-Tag meint immer die exakt gleiche URL. Zu beachten ist allerdings, dass dies nicht mehr für parametrische URLs mit zum Beispiel einer Session-ID gilt. Hier muss dann der Canonical greifen und auf die Stammform verweisen.
Wir haben Canonicals standardmäßig auf noindex gesetzt. Ist das so richtig?
Thomas: Canonicals und Noindex sind einander widersprechenden Konzepte, damit können sie nicht gleichzeitig auf die gleiche URL angewendet werden. Entweder ist der Inhalt eine Kopie und soll einer kanonischen Variante zugerechnet werden oder der Inhalt soll, aus welchen Gründen auch immer, nicht im Index erscheinen.
Kann ich mir in der Searchmetrics Suite Canonical Tags anzeigen lassen, die auf Fehlerseiten (4xx) oder Weiterleitungen (3xx) verweisen?
Malte: Ja, eine solche exportierbare Liste lässt sich durch Kombination der Filter [Status-Code der Ziel URL = 3xx] und [Link-Typ = Canonical] ganz schnell erzeugen.
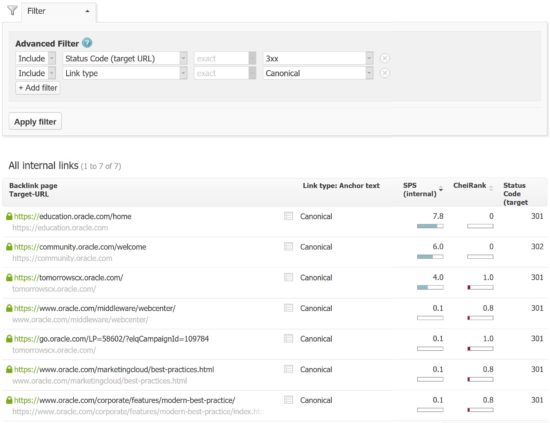
Diesen Report wird es zeitnah in einer überarbeiteten Version geben, mit der man schneller zum Next-Step gelangt. Stay tuned!
Sollte das Canonical Tag in den Head-Bereich der Seite?
Thomas: Der Canonical-Tag muss immer im Head-Bereich der HTML-Webseite eingebaut werden und nicht im <body> der Seite. Alternativ kann die Canonical-Information auch im x-robots-tag des HTTP-Headers übertragen werden. Dieses Vorgehen kann man zum Beispiel nutzen, um PDF-Dateien mit einer Canonical-Information zu versehen.
Sollte man “zur Sicherheit” ein Canoncial Tag einer URL auf sich selbst setzen – oder schadet das?
Thomas: Ja, der sog. selbstreferentielle Canonical-Tag sollte immer eingebaut werden, damit jede originäre URL auf sich selbst als Original verweist. Dies hat den Vorteil, dass, wenn der Webseiteninhalt von Content-Dieben komplett kopiert wird, im Quellcode immer noch die Referenz auf das Original erhalten bleibt. Des Weiteren gibt es immer den Verweis zur Stamm-URL, falls an eine URL zum Beispiel Tracking-Parameter angehängt werden.
Ist es negativ, wenn Kategorieseiten auf parametrisierte Produkt-URLs (mit Canonical auf sich selbst) linken, anstatt direkt auf die Produkt-URLs?
Thomas: Intern sollte man immer direkt verlinken, d.h. ein interner Link sollte keine Weiterleitung haben oder per Canonical auf eine andere URL verweisen. Dies macht sonst den Eindruck einer schlecht gepflegten Webseite, schwächt den Link-Juice der internen Verlinkung und kostet immer auch etwas Ladezeit. Dass Parameter-Einstellungen von der Kategorie zur Produktseite mit übergeben werden, ist zwar sinnvoll und über URL-Parameter lösbar, aber lässt sich über z.B. Cookies viel moderner und komfortabler umsetzen.
SEO-Stolperfalle #2: Paginierung
Sollte eine paginierte Seite 1 auch keinen Canonical haben oder gilt dies erst ab Seite 2?
Thomas: Doch, die muss auch einen Canonical-Tag haben und zwar auf sich selbst. Auch in der Pagination gilt, dass jede Paginations-URL per Canonical auf sich selbst verweist. Allerdings wäre es falsch, per Canonical von der dritten Paginations-Seite auf die erste Seite zu verweisen, denn der Inhalt der beiden Seiten wird nicht identisch sein. Zusätzlich sollte in der Pagination der Prev/Next-Tag verwendet werden, um die Zusammengehörigkeit der einzelnen Listenseiten zu verdeutlichen.
Ist es ein Problem, wenn das Prev/Next Tag verwendet wird und das Canonical-Tag auf die Seite selbst verweist?
Thomas: Nein ist es nicht, beides sind sich ergänzende Konzepte. Durch Prev/Next wird die Zusammengehörigkeit der Listenseiten klar gemacht. Durch den Canonical-Tag wird die Eindeutigkeit der Paginations-URL erklärt, indem diese auf sich selbst verweisen. Auch diese können weitere Parameter angehängt bekommen und damit Varianten erzeugen, welche durch den Canonical-Tag auf eine Stammform zurückgeführt werden.
SEO-Stolperfalle #3: Mehrsprachigkeit
Wie wird “hreflang-x-default” richtig verwendet?
Thomas: Mit dem Hreflang gebe ich an, in welchen Sprachvarianten meine Webseite vorliegt. Für Besucher aus einer spezifischen Region oder mit einer bestimmten Sprache wird dann die genau passende Version ausgespielt. Für alle anderen Besucher gibt es eine Fallback- bzw. Default-Sprache, damit diese auch eine passende Version erhalten und nicht einfach die, die am besten rankt. Der “x-default” sollte deswegen immer angegeben werden und bei großen internationalen Webseiten wird dies meist die englische Variante sein.
Wenn hreflang nicht sauber eingebaut ist, wie negativ wirkt sich das auf die SEO aus?
Malte: Nachfolgend zeige ich euch das Beispiel eines erfolgreichen Onlineshops. In den Jahren 2014 und 2016 gab es Probleme mit den hreflangs. Sofort hat die .de-Domain (blau) angefangen, in Österreich zu ranken. Parallel dazu ist die .at-Domain (orange) eingeknickt:
Thomas: Das kann sich monströs auswirken. Ich gebe mal ein Beispiel, das wir gerade erst bei einem Kunden gesehen haben: Der Kunde ist schon relativ lange in Frankreich und den Niederlanden aktiv und jetzt erstellte er eine zusätzliche Seite für den belgischen Markt, die letztendlich auch die französische und niederländische Sprache abdeckt. Auf google.be hatte bis dato immer entweder die kunde.nl-Domain oder die kunde.fr-Domain gerankt – jetzt kommt auf einmal die neue Seite daher. Die soll ein für Belgien besser passendes Sortiment abbilden und genauer auf die Belgier zugeschnitten sein; allerdings war kein hreflang drauf.
Also hat Google diese nicht ranken lassen; stattdessen ranken die niederländische und die französische Variante einfach weiter. Sie werden wahrscheinlich schlechter geklickt, als eine belgische Seite geklickt werden könnte und konvertieren vielleicht sogar schlechter. Also rankt die falsche Seite und hier braucht es dringend das hreflang, um auszusteuern, was in welchem Land ranken soll – vor allem, wenn ihr gleichsprachige Länder habt, also Deutschland, Österreich und die Schweiz oder eben das Belgien-Beispiel. Um Duplicate Content zu vermeiden und im Extremfall nicht sogar eure Original-Domain in Mitleidenschaft zu ziehen, ist das hreflang ein absolutes Muss.
Wie steht ihr zu automatisierten Redirects auf z.b. /de oder /en anhand der Browsersprache?
Thomas: Dass Nutzer automatisch in das für sie passende Sprachverzeichnis redirected werden, ist kein Problem, solange einige wichtige Punkte beachtet werden. Zunächst ist dieser Redirect ein temporärer 302(!) Redirect, da nicht jeder User in das gleiche Verzeichnis geführt wird, sondern dies dynamisch je nach Browsersprache geschieht. Die einzelnen Sprachverzeichnisse müssen sich gegenseitig per hreflang verweisen und zwischen den einzelnen Varianten sollte es eine Option zum Wechseln geben, damit der Google-Crawler, einem HTML-Link folgend, alle Varianten erfassen kann und nicht nur die englische Version sieht.
Wenn es eine bayerische Sprachversion der Website gibt, was empfiehlt sich da bezüglich hreflangs?
Thomas: Das ist eine sehr gute Frage. Wie nah hängt das Bayerische semantisch am Deutschen? Ganz weit entfernt, nah zusammen? Im hreflang ist nicht vorgesehen, dass ich Bayerisch hinterlege. Als Country Code ist nur Deutsch als Sprache verfügbar. Deshalb kann ich Bayerisch, Hessisch und andere Mundarten nicht darüber abbilden und müsste mir andere Strategien überlegen, um Duplicate Content zu verhindern.
Malte: Ich würde das hreflang-Konstrukt wirklich nur für die Sprache bauen, die ich gut unterstütze. Ob Bayerisch und Plattdeutsch eigene Sprachen sind oder Dialekte, dazu gibt es auch lange Abhandlungen.
Kann man bei unterschiedlichen TLD-Versionen einer Seite – etwa example.dk und example.de – auf das hreflang verzichten?
Thomas: Zunächst: Wenn ich es nicht mache, habe ich zumindest nicht das Duplicate Content Problem. Allerdings ist es absolut sinnvoll, das hreflang einzusetzen, weil ihr euren neuen Länderseiten damit helfen könnt. Nehmen wir an, ihr habt eine DE-Seite und launcht jetzt eine neue Version in Dänemark. Ihr habt euch in Deutschland einen bestimmten Trust aufgebaut. Wenn Google also eure DE-Domain mag, dann sagt ihr dem Google-Crawler mit einem hreflang-Tag: „Ich hab sowas nochmal in Dänemark, willst du das nicht mal ausprobieren?“ Es macht einfach Sinn, Google so etweas zu sagen, wenn sie euch schon vertrauen.
Malte: Vor ein paar Jahren war es noch so, dass ein richtig krasser SEO-Boost zu spüren war über die Canonicals über Sprachen und Domains hinweg, Mittlerweile habe ich das Gefühl, dass es nicht mehr so ist – also nicht wirklich messbar. Aber ich glaube auch, dass der Trust einfach übertragen wird und es ein wichtiges Signal an Google ist: „Hey, diese neue dänische Domain gehört wirklich zu dieser deutschen Domain und hat den gleichen Trust-Level verdient.“ Besonders um Brands zu beurteilen ist das wichtig, weil man ja vielleicht dann keine eigenen Social-Kanäle, Wikipedia-Einträge oder Branchenverzeichnis-Einträge in neuen Land hat – alles Dinge, mithilfe derer Google erkennen Entitäten und Trends erkennen kann.
Was für einen hreflang muss ich angeben, wenn dieselbe Seite für Deutschland, Schweiz und Österreich gelten soll? Kann ich mehrere hreflang pro URL angeben?
Thomas: Wenn ich für den DACH-Raum keine länderspezifischen Inhalte habe, sondern lediglich die gemeinsame deutsche Sprache referenzieren möchte, dann weise ich nur eine .de-Version aus, also die in deutscher Sprache ohne Ländereinschränkung. Diese wird dann für alle Länder mit einer deutschen Sprache ausgespielt.
Natürlich kann ich je URL auch mehrere hreflang angeben, wenn meine /de-1/ URL zum Beispiel für Deutschland, Österreich und die Schweiz ist, während meine /de-2/ URL der Default für alle anderen deutschsprachigen Besucher sein soll.
Hier muss man allerdings genau aufpassen, dass man keine Widersprüche oder unnötigen Duplicate Content erzeugt.
SEO-Stolperfalle #4: Noindex, Nofollow & Robots.txt
Kann es passieren, dass ein Suchmaschinen-Bot die Robots.txt ignoriert oder eingeschränkt liest, wenn diese eine gewisse Größe bzw. Anzahl an Disallow-Befehlen beinhaltet?
Thomas: Bei der Dateigröße habe ich noch nie Probleme gesehen. Fakt ist erstmal folgendes: Die großen Suchmaschinen halten sich weitestgehend an die Standards, die in der robots.txt stehen. Aber: Umso mehr drinsteht, desto mehr Problemquellen werden theoretisch erzeugt.
Es gibt z.B. Suchmaschinen, die damit umgehen können, dass man als erstes Argument sagt: Ich disallowe alles. Also in anderen Worten sagt man z.B. Google: “Du darfst nirgendwo hingehen” und im zweiten Schritt definiert man dann die Ausnahmen, die doch allowed sind. Das kann bei manchen zu Problemen führen. In anderen Worten, umso komplexer die robots.txt ist, umso größer die Fehlerquellen. Wir müssen das so sehen: Ich habe ja gezeigt, dass man sich in der Google Search Console angucken kann, wie Google damit umgeht. Bei Bing wüsste ich gar nicht, ob sie sowas haben und andere wahrscheinlich auch nicht. Deswegen ist mein Tipp eigentlich immer, in der robots.txt alles so unkompliziert wie möglich lassen und für die anderen Themen wie Indexierung und so weiter andere SEO-Mittel zu verwenden. Aber nicht die robots.txt, weil das Fehlerpotenzial einfach enorm ist.
Malte: Ja, deckt sich auch mit meinen Erfahrungen, also bei der robots.txt sollte man sehr, sehr vorsichtig sein. Es gibt ganz wenige Domains wie Wikipedia zum Beispiel, wo es aufgrund des Crawl Budgets wirklich Sinn macht, große Teile der Seite auszusperren. Aber in den meisten Fällen will man ja, dass Google sich die Seiten anguckt, auch wenn sie eventuell Canonical- oder Noindex-Anweisungen werden. Und da würde ich dann immer auf Seitenebenen mit diesen Elementen arbeiten – also noindex, nofollow, canonical; einfach, um sich den internen Link da nicht zu zerschießen.
Stimmt es dass Google disallow und noFollow als negatives Signal wertet – weil Google abwertet, was es nicht sehen kann?
Thomas: Seitenbereiche zu sperren oder mit einem nofollow zu versehen, ist an sich erstmal nichts negatives. Allerdings geht bei allen URLs die zwar intern verlinkt sind, aber dann gesperrt sind, interner Link Juice verloren. Insofern habe ich einen indirekten negativen Effekt, wenn nicht alle verlinkten Inhalte für Suchmaschinen zugänglich sind. Hier ist es besser, die Webseite so zu bauen, dass alle per HTML-Link verknüpften Seiten von Suchmaschinen erfasst werden können, während zum Beispiel Warenkörbe und Login-Bereiche durch andere Techniken aufgerufen werden.
Wenn ich via JavaScript ein noindex oder canonical einfüge, funktioniert das?
Thomas: Ja, das funktioniert, aber es ist keine robuste Lösung, um diese wichtigen Informationen an Suchmaschinen weiterzugeben. Das Problem ist, dass JavaScript erst zeitverzögert ausgeführt wird, im Gegensatz zu den Angaben, die direkt im initialen HTMl-Code hinterlegt sind. Hierdurch werden Noindex- oder Canonical-Anweisungen mitunter erst nachträglich gesehen und könnten sich im Extremfall auch mit denen des HTML-Codes widersprechen.
Was ist der Unterschied zwischen noindex im Robots-Tag (nicht sichtbar im Quellcode) und noindex im Head-Bereich, also in den Quellcode eingebaut?
Thomas: Generell gibt es keinen, also sagen wir mal so: Es steht in einem unterschiedlichen Bereich, aber es macht genau dasselbe. Google hält sich an beides. Der Unterschied ist: Wenn es im Quelltext oben im Head-Bereich steht, könnt ihr einfacher diagnostizieren, ob es da ist oder nicht. Wenn es im HTTP-Header steht, dann wird es ein kleines bisschen schwieriger. Ja, es geht auch und letztendlich ist es so, dass das, was über den Header kommt, meistens über die Server Konfiguration läuft und das, was über den Quelltext kommt, vielleicht sogar CMS-seitig. Aber für Google ist es egal, wo das drin steht.
Malte: In Sachen Wartbarkeit der Seite ist es einfacher, diese Anweisung ins HTML zu integrieren; vor allem für technisch nicht so versierte Webseiten-Betreiber. Dies ist ja via CMS möglich. Wenn der Wettbewerb nicht so SEO-fit ist nd man verstecken will, was man so noindext hat, kann es vielleicht interessant sein, das Ganze im Header zu verstecken. Aber natürlich wird das auch jeder smarte SEO, der ein Tool benutzt, rausfinden.
Online-Shops haben URLs wie Mein Konto, Zur Kasse gehen, Warenkorb, Login. Sollten interne Links mit einem nofollow-Attribut versehen werden oder mit nem Follow-Link?
Thomas: Also mir fallen ganz wenige Fälle ein, wo ich überhaupt noch ein nofollow verwenden würde. Nofollow ist immer schlecht, weil es den Bot aussperrt und weil er nicht weiterkommt. Klar, er soll jetzt nicht auf “Zur Kasse” draufkommen. Aber generell löse ich das lieber anders. Wenn ich wirklich will, dass der Crawler nicht mal mehr auf die URL draufkommt, dann verlinke ich vielleicht mit PRG-Pattern. Auf jeden Fall gebe ich der URL den noindex mit, aber mir fallen keine sinnvollen Fälle ein, nofollow an einen Link ranzupacken.
Malte: Ganz früher hat man ja das PageRank Sculpting damit gemacht, aber mittlerweile verpufft damit einfach nur noch Linkjuice und wie gesagt, außer so ein paar Ausnahmen, wo es wirklich dann um Crawl-Budget geht wegen Millionen von Seiten, würd ich auch nofollow intern gar nicht benutzen, also da gibt es andere Mechaniken.
Sollten Checkout-Seiten bei einem Online Shop in der robots.txt per disallow ausgeschlossen werden oder über noindex? Wie sollte alternativ mit diesen Verfahren werden?
Thomas: Checkout-Seiten sollten im Idealfall nicht als HTML-URL verlinkt sein, sondern über andere Web-Techniken, wie eine JavaScript-Maskierung, erreichbar sein. Sind diese URLs bereits im Index, so können sie per noindex-Tag wieder entfernt werden. Sind die URLs noch nicht im Index, so können sie per robots.txt blockiert werden.
Wenn eine URL nicht im Index aufgenommen werden soll, sollte dies dann per noindex oder per robots-Metatag geregelt werden?
Thomas: Eine Indexierung verhindert man per noindex-Tag, während die robot.txt lediglich das Crawling der Inhalte verbietet, aber nicht die Indexierung. Zeigen zum Beispiel viele externe Links auf eine URL, so wird diese von Suchmaschinen als wichtig erkannt und in den Index aufgenommen. Eine robots.txt Blockierung verhindert dann nur, dass ein passendes Snippet zur URL angezeigt werden kann, da ja der Inhalt der Seite nicht angeschaut werden darf.
Wie kann verhindert werden, dass eine Seite von Google indexiert wird – obwohl der Bot per disallow ausgeschlossen und ein zusätzliches noindex auf der Seite selbst eingefügt wurde?
Thomas: Per Definition widersprechen sich eine robots.txt-Blockierung und ein noindex-Tag. Per robots.txt wird das Crawling der Inhalte blockiert, aber nicht deren Indexierung. Der noindex-Tag unterbindet die Indexierung, aber benötigt eine robots.txt-Freigabe, um die URL und deren Quellcode crawlen zu können, damit der noindex-Tag im <head> erfasst werden kann. Insofern muss man zur Verhinderung einer Indexierung den noindex-Tag einbauen, muss aber gleichzeitig das Crawling der URL per robots.txt erlauben.
Ist der Einsatz von nofollow für externe Links noch sinnvoll? In welchen Fällen?
Thomas: Gerade für externe Links, die ich selbst nicht unter Kontrolle habe und die zum Beispiel durch Weiterleitungen oder Inhaltsänderungen in ihrem Sinngehalt verändert werden können, ist der nofollow-Tag wichtig. Dies ist vor allem in Bereichen wichtig, wo User selbst URLs und Inhalte hinterlegen können, wie zum Beispiel Foren oder Gästebücher. Hier entwerte ich als Webmaster per nofollow pauschal alle eingetragenen URLs, da ich nicht alle manuell prüfen bzw. ihre Konsistenz im Zeitverlauf nicht garantieren kann. Dass ich als Forenbetreiber nicht nur die ausgehenden Links und deren Qualität prüfen sollte, sondern bei den gleichzeitig hochgeladenen Texten und Bildern eventuelle Urheberrechtsverletzungen verhindern muss, ist nochmal ein ganz anderes Thema.
SEO-Stolperfalle #5: Sitemaps
Braucht jede Website eine XML-Sitemap? Macht eine Sitemap bei einer Website mit nur 100 Seiten überhaupt Sinn?
Thomas: Für das Crawling einer Webseite mit nur wenigen URLs ist die XML-Sitemap nicht unbedingt notwendig, da das Crawl-Budget im Normalfall ausreicht, um regelmäßig alle URLs neu anzuschauen. Allerdings hilft eine Sitemap dabei, zum Beispiel News-Inhalte schneller und gezielter an Suchmaschinen zu übermitteln, da dort immer die neuesten Beiträge aufgeführt werden. Ebenso hilft die XML-Sitemap bei der Fehlersuche und Indexierungskontrolle einer Domain, denn ich kann je Seitentyp und Verzeichnis eine Sitemap in der Google Search Console hinterlegen und erhalte so für jede dieser Sitemaps eine Rückmeldung, ob es Probleme beim Crawling gab und ob alle URLs indexiert wurden.
Wenn ich eine XML-Sitemap habe, muss sie vollständig sein? Oder reicht es, wenn nur die wichtigsten URLs in der Sitemap sind?
Thomas: Eine Sitemap muss nicht vollständig sein, sondern kann zum Beispiel auch nur die neuesten URLs enthalten. Allerdings hilft mir eine vollständige Sitemap aller URLs, die ich indexiert haben möchte, bei der Überwachung der Indexierung. In der Google Search Console erhalte ich dann eine Rückmeldung zur Vollständigkeit und zu eventuellen Problemen beim Crawling.
Macht es einen Unterschied in der Sitemap mit <changefreq> oder mit <lastmod> zu arbeiten?
Thomas: Die Angabe <lastmod> in einer Sitemap gibt an, wann der Inhalt der URL das letzte Mal geändert wurde und sollte immer mit angegeben werden, da Google diesen Wert berücksichtigt und zur Crawling-Steuerung nutzt. Die <changefreq> sagt hingegen aus, wie oft der Inhalt geändert wird. Dies wird von Google nicht beachtet, da Webmaster diesen Wert nie korrekt befüllt haben. So wurde versucht, durch eine höhere Change-Frequenz als in der Realität zutreffend den Anschein häufiger Inhaltsänderungen zu erwecken und damit ein häufigeres Crawling zu erreichen, um zum Beispiel Änderungen an den Title-Tags schneller indexiert zu bekommen.
Darf ein Sitemap-Index weitere Indizes beinhalten? John Müller riet vor Kurzem davon ab!
Thomas: Die Anzahl an URLs pro Sitemap ist nicht unlimitiert, sondern ist auf 50.000 begrenzt. Um eine Domain mit mehr URLs abzubilden, muss die Sitemap in mehrere Teile aufgeteilt werden, welche dann wiederum alle zusammen in einer Index-Sitemap aufgelistet werden. In der neuen Google Search Console ist das Hinterlegen einer Index-Sitemap, welche dann hierarchisch alle untergeordneten Sitemaps verlinkt, aber nicht mehr möglich, darum müssen alle Einzel-Sitemaps separat angemeldet werden. Dies ist ein hoher initialer Aufwand, aber man sieht dann bereits auf der ersten Ebene der Sitemap-Übersicht, ob es in irgendeiner der Sitemaps Probleme gibt, ohne dass man sich von der Index-Sitemap aus in die Tiefe klicken muss.
SEO-Stolperfalle #6: PDFs
Erkennt Google Text in Bildern und in PDFs? Was ist, wenn die PDFs nur gescannte Texte (=Bilder) sind?
Thomas: Natürlich ist Google inzwischen in der Lage, den Text in Bildern auszulesen und darüber hinaus auch Objekte und Gegenstände zu erkennen. Allerdings wird dies nicht für jedes Bild gemacht und auch nicht sofort beim Crawling eines neuen Bildes. Darum ist das keine Möglichkeit, auf die man sich verlassen sollte, um Inhalte in den Index oder zum Ranken zu bekommen. Zum Anderen erscheinen Bilder in der Bildersuche nur bedingt durch deren direkten Inhalt, sondern primär durch ihren Dateinamen, das Alt-Tag und den Kontext, in dem sie verwendet werden. Die Bilder in ein PDF einzufügen ändert daran nichts, da vor allem der Name, die Meta-Daten und die reinen Text-Inhalte eines PDF für deren Indexierung herangezogen werden.
Ganz anders ist die Situation aber bei reinen Text-PDFs, welche vom Google-Crawler problemlos ausgelesen und indexiert werden können. Allerdings machen umfangreiche PDF-Inhalte im Vergleich zu HTML-Webseiten nur bedingt als Suchergebnis Sinn, da diese zum Beispiel auf Smartphones eher schlecht nutzbar sind, während Webseiten meist problemlos skaliert und abgebildet werden können.
Wenn PDFs auf index stehen, müssen die denn dann – wie eine normale Content-Seite – auch bestimmte Kriterien bezüglich Aufbau etc. erfüllen?
Thomas: PDF ähnlich wie Content-Seiten zu optimieren, macht auf alle Fälle Sinn. So sind ebenfalls Dateinamen, Meta-Daten, semantische Überschriften, Bildunterschriften und weiterführende Links wichtig. Außerdem ist es sinnvoll, ein Logo mit Link zu der Domain, die das PDF erstellt hat, einzubinden.
Ob PDF-Dateien an sich ein sinnvolles Suchergebnis sind, ist eine andere Frage, denn auf Smartphones werden PDF nur unzureichend dargestellt, da sie nicht wie Webseiten skaliert werden und man immer vertikal und horizontal scrollen muss, um alle Inhalte sehen zu können.
SEO-Stolperfalle #7: Bilder
Ich habe gerade einen Disallow /Images/ in meiner Robots.txt gefunden. Wieso sollte man das machen?
Malte: Wenn mir die Bilder-Rankings egal sind, kann ich dies tun, um Crawl-Ressourcen zu sparen. Wenn ich mir die aktuellen Traffic-Kosten anschaue, sollte es jedoch für die meisten Websites sinnvoll sein, Google das Crawlen von Bildern zu erlauben.

Beispiel: Amazon.de: Für 62% aller Keywords bei denen die Domain Amazon.de in Google rankt, werden Bilder-Boxen als Universal Search Element ausgespielt. In 40% der Fälle stammt mindestens eines der Bilder von Amazon. Würde Amazon Google verbieten würde, die eigenen Bilder zu crawlen, würde auf viele Besucher verzichtet werden.
Thomas: Neben den Rankings in der Bildersuche und dem daraus resultierenden Traffic, ist zu beachten, dass Google die komplette Webseite crawlen und rendern möchte, um den Inhalt und dessen Darstellung vollständig erfassen zu können. Daher macht es keinen Sinn, Bilder und Dateien zu blockieren, um deren Anzeige in der Google-Suche zu verhindern. Stattdessen sollte man mit Wasserzeichen und Logos in den Bildern arbeiten.
Was sind mögliche Fehler, wenn eine große Anzahl an Bildern (laut Search Console) eingereicht sind, aber nicht indexiert werden?
Thomas: Hier kann es vielfältige Gründe geben. Die Bilder können zwar per Image-Sitemap eingereicht werden, aber durch zum Beispiel robots.txt Blockierung vom Crawling ausgeschlossen sein. Im x-robots-Header des Datei-Abrufs vom Server kann ein noindex übermittelt werden. Die Bilder können vom Format her viel zu klein sein, um indexiert zu werden. Des Weiteren können die Bilder falsch in der Webseite eingebunden sein, da zum Beispiel Bilder im src-Attribut oder im CSS-Style eines div-Containers nicht indexiert werden.
SEO-Stolperfalle #8: Redirects
Könnt ihr den Unterschied zwischen Redirect 301, 302, 303 und 307 erklären?
Thomas: Eine 301-Weiterleitung ist des SEOs-Liebling, da diese eine dauerhafte Weiterleitung von A nach B meint, wodurch A aus dem Index der Suchmaschine entfernt und durch B ersetzt wird und das Ranking fast komplett auf B übertragen wird. Die 302-Weiterleitung ist leider die Standard-Einstellung auf vielen Webservern und meint eine temporäre Weiterleitung, wodurch die bisherige URL A im Index erhalten bleibt, im Suchergebnis auch weiterhin die URL A angezeigt wird und auch weiterhin das alte Snippet von URL A angezeigt wird.
Der 303-Redirect ist eine Variante des 302-Redirects und meint “See other”. Hierbei ist wichtig, dass er nur für Server mit HTTP 1.1 funktioniert und die Request-Methode des anschließenden Redirects der GET-Methode entsprechen muss.
Der 307-Redirect gilt unter HTTP 1.1 als Nachfolger des 302-Redirects, allerdings darf hier kein Wechsel der Redirect-Methode stattfinden.
Gibt es eine Anzahl an Redirects, die man nicht überschreiten sollte, um eventuelle negative SEO-Auswirkungen zu vermeiden?
Thomas: Jeder Redirect kostet etwas an Ladezeit und lässt den übertragenen Linkjuice schmelzen. Zudem wird nur eine begrenzte Anzahl an aufeinanderfolgenden Redirects von Google verfolgt (im Normalfall 5), wodurch man Ketten an Redirects immer vermeiden sollte und stattdessen immer direkt von A nach B weiterleiten sollte.
Malte: Gezielt für Redirect Chains wird es bald auch etwas neues von uns geben. Hier schon mal ein kleiner Sneak Peek:
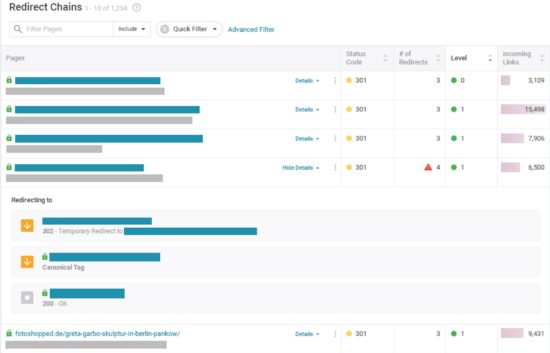
SEO-Stolperfalle #9: Relaunch & Redesign
Was ist zu beachten, wenn die Domain beim Redesign identisch bleibt, der Provider aber gewechselt wird?
Thomas: Wird nur der Provider gewechselt und das Design geändert, aber alle URLs und die komplette Webseitenstruktur bleiben gleich, dann ist wichtig, dass der neue Provider eine gute Netz-Anbindung, hohe Geschwindigkeit und dauerhafte Verfügbarkeit hat.
Stichwort Relaunch: Wenn ich eine Beta-Version unserer Webseite auf der Startseite einbinde, soll ich den Link zur Betaversion maskieren?
Thomas: Wenn die Beta jetzt wirklich nur dafür da ist, um sie einigen ausgewählten Leuten zu zeigen, dann liegt sie sicher auf einer Subdomain. Die würde ich nicht verlinken, weil die anderen Kunden nicht drauf kommen und nicht abgelenkt werden sollen. Es ist jetzt mal die Visibility-Frage. Ich würde über eine htaccess-Sperre dafür sorgen, dass andere Nutzer nicht rauf können. Oder als absolutes Minimum wenigstens über die robots.txt per disallow auf jeder URL dafür sorgen, dass eine Suchmaschine nicht drauf kommt. Dann kann man die URL an die ausgewählten Nutzer verteilen.
Malte: Genau, ich würde sie auch komplett per robots.txt sperren und Google einfach nicht drauf lassen. Und falls Google anfangen sollte, sich nicht an die robots.txt zu halten – was ja manchmal passiert – würde ich den Bot eiskalt sperren, da er sein Crawl-Budget nicht auf der Beta-Version verschwenden soll.
SEO-Stolperfalle #10: 4xx Fehler
Wenn ich viele 404-Fehler habe, wirkt sich das negativ aufs Ranking aus?
Thomas: Einige wenige 404-Fehler sind ganz normal bzw. auch sinnvoll und nötig, um Inhalte und Seitenbereiche, die ich nicht mehr anbiete, aus dem Index von Suchmaschinen entfernen zu lassen. Allerdings macht es keinen guten Eindruck einer gepflegten Webseite, wenn meine interne Verlinkung und Menü-Navigation 404-Fehler aufweist. Dies ist nicht nur für Suchmaschinen eine Einbahnstrasse, sondern vor allem für die Nutzer unbefriedigend.
Was ist der Unterschied zwischen einem 404-Fehler und einem Soft-404-Fehler?
Thomas: 404-Fehler meint Webseiten und Inhalte, die nicht mehr auf der Domain zur Verfügung stehen und damit aus dem Index von Suchmaschinen entfernt werden sollen. Ein Soft-404 Fehler meint hingegen Seiten und Inhalte, die wie eine 404-Seite aussehen, aber keinen 404-Statuscode übermitteln. So können leere Seiten ausgespielt werden oder generelle Redirects zur Startseite erfolgen, die beide wie ein 404-Fehler aussehen, aber keinen entsprechenden Server-Status mit übertragen.
Was mache ich, wenn ich ein Geschäftsmodell wie eBay oder ImmobilienScout24 habe – und die Inserate also nur temporär verfügbar sind? a) Statuscode 200 und Links auf ähnliche Produkte; b) 301 auf die übergeordnete Kategorie, c) 404, d) 410 oder e) via robots.txt blocken?
Thomas:
a) Der bisherige Inhalt bleibt im Index und wird weiterhin als Suchergebnis ausgespielt, aber wird eine schlechte User Experience erzeugen, da das Angebot abgelaufen ist und der User es nicht mehr kaufen kann. Die Links auf ähnliche Produkte sind dann nur ein kleines Trostpflaster und erfordern eine erneute User-Interaktion. Außerdem würde der Index mit diesen abgelaufenen Angeboten immer weiter aufgebläht, was langfristig nicht zu empfehlen ist.
b) Ein Redirect zu einer übergeordneten Kategorie macht meist nur bedingt Sinn, da die Kategorien oft sehr generisch sind und nicht sofort genau das gleiche/ähnliche Produkt gezeigt wird, das man eigentlich gesucht hat.
c) Ein 404-Statuscode scheint das sinnvollste zu sein, da ja genau das eine spezifische Produkt nicht mehr verfügbar ist und nicht mehr angeboten wird. Allerdings kann es auch hier eine schlechte Nutzererfahrung geben, da zum Zeitpunkt des Google-Crawlings das Produkt noch verfügbar war, in der Folge als Suchergebnis ausgespielt wird und den Nutzer unglücklich zurücklässt, da eine 404-Seite statt des Inserates angezeigt wird.
d) Hier ist die Situation ähnlich wie bei c), allerdings impliziert der 410-Statuscode, dass das Produkt dauerhaft nicht mehr angeboten wird und auch kein ähnliches Produkt nachrücken wird. Dies ist eine noch verschärfte Variante des Vorgehens in c).
e) Hierdurch wird lediglich das erneute Crawlen der URLs verhindert, um zum Beispiel deren Snippet oder Indexierungsstatus aktualisieren zu können. Die Inhalte bleiben weiter im Index und werden ausgespielt, aber werden immer mehr “veralten” und die Nutzer immer unzufriedener machen.
Die beste Lösung wäre es natürlich, wenn man gar nicht mit den einzelnen uniquen Produkten ranken würde, sondern mit generischen Listenseiten arbeiten würde, die immer genügend aktuelle und verfügbare Produkte aufweisen und in ihrer Struktur und Keyword-Passgenauigkeit so fein wie möglich auf das Suchverhalten der Nutzer abgestimmt sind.
Weitere Fragen zu den SEO-Stolperfallen
Wieso scannt der Googlebot Dateien auf einem Server, die es nie mit diesem Namen gab?
Thomas: Google ist eine Suchmaschine und versucht, alle Inhalte einer Webseite zu scannen und zu crawlen. Hierdurch werden alle Elemente aufgerufen, die wie eine URL aussehen. So kann es passieren, dass versucht wird, Content-Labels im GfK-Trackingpixel oder im data.Layer des Google Tag Managers aufzurufen, um dahinter liegende Inhalte zu entdecken, die evtl. nicht als Standard-HTML-Link hinterlegt wurden. Hierdurch werden mitunter URLs aufgerufen, die es so gar nicht gibt. Eine Suche im Quellcode kann dann hilfreich sein bzw. auch der Blick auf die externen Verlinkungen, denn auch über externe Verweise können Inhalte referenziert sein, die es so nicht gibt.
Wir haben die TLD .ag und kommen nicht zu Visibilty. Der hreflang und viele andere technische Voraussetzungen sind richtig implementiert. Auch an Content mangelt es nicht. Was können wir machen, um die scheinbaren Defizite der TLD auszugleichen?
Malte: Eine TLD wie .ag ist für zum Beispiel deutsche Nutzer eher ungewöhnlich und wird deshalb schlechter geklickt und rankt deshalb in der Folge auch schlechter. Sind alle technischen und inhaltlichen Faktoren erfüllt, muss man in die klassische Trickkiste der Werber greifen, um diese TLDs bekannt zu machen und die User zum klicken zu bringen. So kann man einerseits ein Content Marketing mit tollen Inhalten auf Domains Dritter starten, welche dann auf einen zurückverwiesen und die .ag Domain bekannt machen. Zum anderen kann man auch klassische Plakat- oder Fernsehwerbung schalten, um die Domain bekannt zu machen. Eine .ag-TLD ist so eher eine klassische Herausforderung für das Marketing, als eine technische oder contentrelevante Baustelle für SEOs.
Wie ermöglicht man HTTP/2?
Thomas: Das hängt davon ab, welche Möglichkeiten euer Server hat. Am besten habt ihr Techniker bei euch im Haus oder ihr fragt bei eurem Hoster nach. Fragt am besten “Wir brauchen HTTP 2” oder “Was ist denn von Nöten, um unsere Webseite über HTTP 2 auszuspielen?”. Dann könnt ihr abschätzen, ob es klappt.
Malte: Genau, ich würde das auch über die IT spielen. Das Schöne ist, wenn alles richtig konfiguriert und sauber aufgesetzt ist, ist es wirklich Schnips und man muss nichts an der Website ändern, nichts am CMS, nichts am Tracking, sondern es läuft einfach sauber.
Was ist die beste Methode, um eine alte Seite vollständig und schnell aus dem Index zu nehmen, damit kein Fehler mehr angezeigt wird, wenn die Seite irgendwann abgeschaltet werden kann?
Thomas: Geht es um eine einzelne URL, so kann man diese mittels der Google Search Console https://support.google.com/webmasters/answer/1663419?hl=de zügig (aber nur temporär) aus dem Google-Index entfernen lassen. Man muss die URL aber parallel mit einem 404- (bzw. 410-)Statuscode versehen, um diese dauerhaft aus dem Index zu entfernen. Soll der Inhalt noch erreichbar sein, so muss man den noindex-Tag, statt dem 404/410-Statuscode verwenden.
Geht es um ganze Verzeichnisse oder Domains, so sollte man diese zunächst in einer Sitemap sammeln, dann alle diese URLs mit einem Noindex-Tag versehen und nach erfolgreicher De-Indexierung die Domain löschen.
Was haltet ihr von AMP-Seiten? Wie relevant sind diese Seiten, um Rankings zu behalten oder zu verbessern?
Thomas: AMP-Seiten sind vor allem wichtig, um im News-Karussell der Google-Suche erscheinen zu können. Ist man ein News-Publisher, so kommt man um AMP nicht herum. Für alle anderen Geschäftsmodelle ist AMP rein aus Pagespeed-Sicht nicht so relevant, da es viele andere Wege gibt, um die Ladezeit der eigenen Inhalte zu beschleunigen. Der Vorteil hierbei ist, dass man nicht an die Restriktionen des AMP-Formates gebunden ist und die Hoheit über die eigenen Inhalte behält.
Wird das AMP-Format auch für andere Verticals als News relevant und eine nahezu Pflicht, dann wird man auch hier AMP einsetzen müssen. Alles Weitere müssen dann die EU-Wettbewerbshüter in Brüssel entscheiden ;-)
Malte: AMP ist das am weitesten verbreitete SERP-Feature. In Deutschland sehen wir AMP-Ergebnisse für 80% bis 84% aller Suchbegriffe.
Searchmetrics Insight: Der Anteil von AMP an Suchergebnissen in Deutschland seit Oktober 2018.
Sollte man Suchergebnisse crawlen lassen? Also im Shop zum Beispiel?
Thomas: Ich würde mal so sagen: Im normalen Onlineshop möchte ich nicht, dass meine Suchergebnisse gefunden werden, aber das ist ja nicht Gegenstand der Frage. Und im Grunde genommen will ich ja eigentlich auch nicht, dass sie gecrawlt werden, denn ihr habt ein beschränktes Crawling-Budget und das sollte der Google-Bot lieber verwenden, um über Hauptkategorien und Pagination eure neuen Produkte zu finden. Wenn ihr Suchergebnisse so rausgebt, dass Google auf die URLs kommt und problemlos crawlen kann, dann können es theoretisch unendlich viele Seiten sein, je nachdem, was es noch für Probleme gibt. Deswegen will ich generell nie solche dynamischen Seiten gecrawlt haben, sondern die Seiten, die ihr standardmäßig im Shop drin habt – also Kategorieseiten und vielleicht noch einige eurer Filter-URLs. Es gibt Ausnahmen, wo es irgendwie Sinn gemacht hätte, aber weniger im Ecommerce-Bereich, eher bei anderen Seiten. Aber die sind rar gesät. Ich würde sagen, es macht in 99 Prozent aller Fälle keinen Sinn, da Crawling-Budget hinzuschicken.
Malte: Genau. Die Ausnahme ist vielleicht noch, wenn man ein sehr cleveres Setup hat und mit diesen Suchseiten ganz schnell Landingpages für einen aktuellen Trendterm bauen kann, für den sich noch kein großer Arbeitsaufwand im CMS lohnen würde. Das heißt, es kann manchmal Sinn machen, mit sowas wie einem PRG-Pattern, also Post/Redirect/Get, einen Großteil der Suchseiten und Filterseiten auszuschließen und dann aber so 4-5 Beispiele einfach zuzulassen, um mal schnell eine Landingpage zu haben. Aber standardmäßig sollte man das ausschließen, weil es so zu viele URLs werden.
Wenn ich eine Mobile-First-Indexing-Notification bekommen habe, muss ich dann mit mobilem User Agent crawlen und meine interne Verlinkung zu analysieren?
Thomas: Ja, das Crawling per Mobile-UA macht Sinn, um genau die Ansicht zu erhalten, die auch der mobile Googlebot haben wird. So kann es sein, dass das Webseiten-Template zwar als responsiv beschrieben wird, aber in der mobilen Ansicht nicht alle Texte, Links und Markups ausgespielt werden. Dem kommt man nur auf die Schliche, wenn auch das Crawling mit einem Mobile-UA stattfindet.
Ignoriert Google wirklich Meta Refresh? Das wäre dann doch ein Freifahrtschein zum Cloaking!
Thomas: Ja genau, früher wurde dies genauso genutzt, aber seit einigen Jahren führt Google die Webseite aus und ruft nicht nur den Quellcode ab, d.h. die Webseite wird komplett gerendert und dann fallen derartige Techniken auch auf. Des Weiteren steht der Meta-Refresh auch direkt im <head> der Webseite und kann so einfach gefunden werden.
Du machst ein Audit einer Domain mit 200.000 URLs. Natürlich gibt es viele technische Baustellen. Wie gehst du vor, um die Next Steps mit dem größten Impact abzuleiten?
Thomas: Beim Audit von großen Webseiten ist es zunächst wichtig, alle Informationsquellen zur Webseite anzuzapfen. Neben einem kompletten Crawl der Webseite sind die Daten der Search Console und des Webtracking entscheidend. In all diesen Daten sucht man zunächst nach Mustern, um Fehler zu finden, die immer wieder auftauchen, aber letztendlich auf die gleiche Ursache im Template, der Server-Konfiguration oder der internen Verlinkung zurückzuführen sind.
Aus der kompletten Liste aller Fehler ergibt sich so eine Matrix der Fehler, die häufig auftreten und die auf verschiedene Ursachen zurückzuführen sind. Oft kann man dort schon nach Aufwand und Summe der damit behebbaren Fehler priorisieren.
Hat man Fehler, die einen ähnlichen Aufwand bedeuten, so sollte man diese danach priorisieren, ob gravierende Duplicate-Content-Probleme beseitigt werden, die Ausspielung der Titles und Descriptions wesentlich verbessert wird, die Seiteninhalte komplett crawlbar werden, indem zum Beispiel JavaScript und Pre-Rendering korrigiert werden oder die Ladezeit und mobile Darstellung wesentlich verbessert werden.
Andere Probleme, die entweder nur wenige URLs betreffen oder nur Schönheitskorrekturen an den Templates und URLs bringen, können dem eher nachgeordnet werden.
Verpasst nicht die weiteren Webinare mit Searchmetrics & LEAP! Am 20 März geht’s um den Website-Relaunch – was dabei schief gehen kann, was ihr im Hinblick auf SEO unbedingt beachten solltet und wie ihr nach dem Relaunch besser darsteht als zuvor. Und am 17. April 2019 geht’s um SEO für Bing. Ihr lernt, wie die Bing Webmaster Tools funktionieren, was anders ist als bei Google und wie ihr Bing am besten nutzen können.