
Der Knowledge Graph ist Googles semantische Datenbank. Hier werden Entitäten in Beziehung zueinander gestellt, mit Attributen versehen und in thematischen Kontext bzw. Ontologien gebracht. Doch was ist denn eine Entität? Und wie genau funktioniert denn der Knowledge Graph? Dazu mehr in diesem Gastbeitrag von Olaf Kopp, der Teil 3 in der Artikelserie zu Semantik und Machine Learning bei Google ist.
Wer Teil 1 noch nicht gelesen hat, kann dies hier tun: Wie interpretiert Google heute Suchanfragen? Und zu Teil 2 geht es hier: Was bedeuten Semantik und Machine Learning für die Google-Suche?

Semantik = Entitäten plus Ontologien
Die wichtigsten Elemente einer semantischen Grundstruktur sind Entitäten und Ontologien. In der Semantik ist eine Entität eindeutig durch einen Identifier und bestimmte Eigenschaften (Attribute/Properties) gekennzeichnet. Während der Indentifier (URI), meistens in Form einer Zahlenreihe, zur Identifikation durch Maschinen gedacht ist erkennen Lebewesen Entitäten anhand derer Eigenschaften.
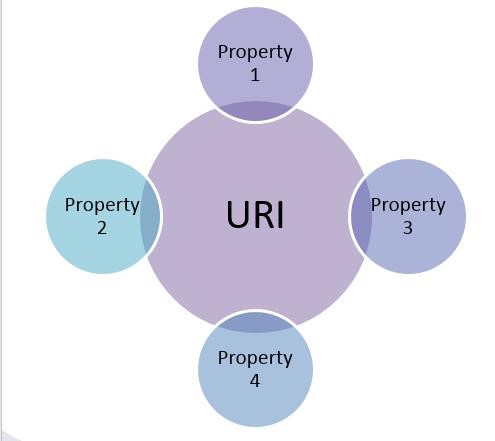
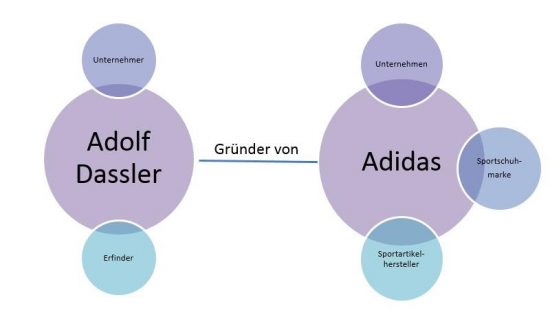
Entitäten sind immer Teil einer Ontologie. Ontologien beschreiben das Umfeld in dem Entitäten verortet sind. Verdeutlichen wir das Ganze mit einem Beispiel für die Entitäten Adolf Dassler, Adidas, Reebok und Footlocker. Adolf Dassler ist Unternehmer sowie Erfinder ist der Gründer des Sportartikelherstellers Adidas:
Reebok ist ein Tochterunternehmen von Adidas und die Sportartikel-Handelskette Footlocker ist Kunde von Adidas sowie Reebok verkauft Artikel wie z.B. den Adidas Superstar oder den Reebok Freestyle:
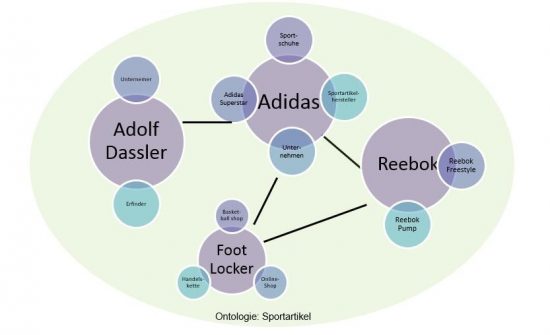
Zur Verbildlichung semantischer Strukturen wird sich gerne der Graphentheorie bedient. Auf dieser Theorie basieren u.a. der Knowledge Graph von Google oder der Facebook Graph.
Graphen bestehen aus Knoten und Kanten. Im Kontext der Semantik sind die Knoten die Entitäten und die Kanten stellen die Relationen verschiedener Entitäten zueinander dar. Die Relationen können auch mit Werten versehen werden wie z.B. einem „Relationskontext“. Im obigen Beispiel von Adolf Dassler zu Adidas wäre es „Gründer“.
Ein Graph enthält alle beteiligten Entitäten, unabhängig von der Ontologie. Kanten können neben der reinen Darstellung einer Beziehung zwischen Entitäten auch zur Bewertung dieser Beziehungen z.B. in Länge und Dicke genutzt werden. Eine besonders ausgeprägte Relation, was die „Dicke der Verbindung“ angeht, kann eine intensive Beziehung der beiden Entitäten darstellen. Ebenfalls kann die Beziehungs-Entfernung zweier Entitäten zueinander zur Darstellung der Nähe zueinander genutzt werden. Darüber hinaus lässt sich auch eine Brücke zu Vektorräumen inkl. euklidischen Abständen herstellen. Sprich: Eine Graphen-Struktur ließe sich über statistische Verfahren wie Vektorraumanalysen ableiten.
Was ist eine Entität für Google?
Entitäten sind für Information Retrieval Systeme von besonderer Bedeutung, da über sie im Rahmen der Textverarbeitung zusätzliche implizite Informationen zum Kontext der Suchanfrage, eines Satzes oder Textabschnitts in dem eine oder mehrere Entitäten bzw. deren Relationskontext verwendet werden erschlossen werden können.
Die eindeutige Identifikation von Entitäten ist für Google aus verschiedenen Perspektiven wichtig:
- Interpretation der Suchanfragen
- Eindeutigkeit bei Mehrfach-Bedeutungen
- Identifikation von Beziehungen von Entitäten untereinander sowie deren Bedeutung hinsichtlich Ontologien bzw. Themen
- Interpretation von Dokumenten
- Identifikation von relevanten Entitäten im thematischen Kontext
Theoretisch gibt es eine Vielzahl an Entitäts-Arten wie z.B.
- Bücher
- Bildungseinrichtungen
- Events
- Behörden
- Unternehmen
- Filme
- Serien
- Musikgruppen
- Organisationen
- Personen
- Orte
- ….
Ein Blick auf die Entitätstypen bei schema.org gibt einen kompletten Überblick darüber, was als Entität aufgefasst werden kann. Es ist nicht ganz einfach zu beurteilen, was Google nun als Entitäten bezeichnet. In einer Patenbeschreibung auf das sich Google in einem eigenen Patent bezieht findet man folgende Definition:
A named entity is a group of one or more words (a text element) that identifies an entity by name. For example, named entities may include persons (such as a person’s given name or role), organizations (such as the name of a corporation, institution, association, government or private organization), places(locations) (such as a country, state, town, geographic region, a named building, or the like), artifacts (such as names of consumer products, such as cars), temporal expressions, such as specific dates, events (which may be past, present, or future events, such as World War II; The 2012 Olympic Games), and monetary expressions. Quelle: https://www.google.com/patents/US20100082331
Es wirkt so, als ob Google relevante Entitäten in den Knowledge Graph Boxen rechts von den Suchergebnissen (Search Engine Result Pages, kurz SERPs) darstellt. Ich nenne sie deshalb auch gerne Entitäten-Boxen. Alles, was oberhalb der SERPs etwa als Direct-Answer-Box bzw. Featured Snippet Box dargestellt wird, sind eher Konzepte bzw. Themen. Die Karussell-Darstellungen ganz oben beziehen sich z.B. auf Events, Filmen, Serien.
Wenn man sich die Entitäten Boxen mal genauer ansieht, kommt man zu dem Schluss, dass
- Personen
- Unternehmen
- Tiere
- Bauwerke
- Städte/Orte
eine besondere Rolle als Entitäten spielen.
Bei den Entitäten-Boxen muss man unterscheiden zwischen Entitäten-Boxen, die sich auf Informationen aus Google My Business (regionale Unternehmen), Google+ (Personen) oder dem Knowledge Graph (Unternehmen, Personen, Tiere, Bauwerke, Städte/Orte) beziehen. Die Informationen in den Entitäten-Boxen, bezogen auf My Business und Google+, kann man größtenteils selbst bestimmen.
Woher bezieht Google die Knowledge-Graph-Infos?
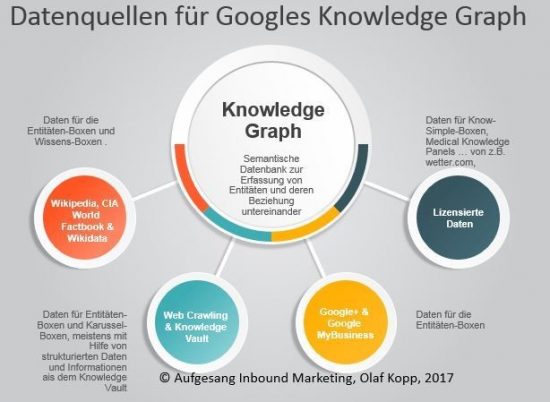
Die Informationen zu den Entitäten und deren Beziehungen untereinander bezieht aus Google aus folgenden Quellen:
- CIA World Factbook, Wikipedia / Wikidata (ehemals Freebase)
- Google+ beziehungsweise Google My Business
- Strukturierte Daten (schema.org)
- Web-Crawling
- Knowledge Vault
- Lizensierte Daten
Der Knowledge Graph ist Googles semantische Datenbank. Hier werden Entitäten in Beziehung zueinander gestellt, mit Attributen versehen und in thematischen Kontext bzw. Ontologien gebracht. Die Entwicklung des Knowledge Graph durch Google scheint eng mit dem Kauf der semantischen Wissens-Datenbank Freebase in Verbindung zu stehen. Ich bezeichne Freebase auch gerne als Spielplatz, über den Google die ersten Erfahrungen mit strukturierten Daten machen konnte.
Im Jahr 2012 führte Google dann den Knowledge Graph ein, der anfangs u.a. durch die in Freebase gesammelten Daten und Wikipedia gespeist wurde. Das offene Projekt Freebase wurde 2014 beendet und in das geschlossene Projekt Wikidata überführt. Für die Darstellung einer Entitäten-Box prüft Google, ob ein Datensatz in Wikidata oder eine Seite bei Wikipedia vorhanden ist.
In einem wissenschaftlichen Projekt, an dem auch ein Google-Mitarbeiter beteiligt war, wird eine Entität gleich gesetzt mit einem Wikipedia-Beitrag.
“An entity (or concept, topic) is a Wikipedia article which is uniquely identified by its page-ID.”
Wikipedia-Beiträge spielen bei vielen Knowledge Graph Boxen eine übergeordnete Rolle als Quelle der Informationen und werden von Google neben den Wikidata-Einträgen als Proof für die Relevanz einer Entität genutzt. Ohne Eintrag bei Wikipedia oder Wikidata keine Entitäten-Box.
Welche zentrale Rolle die Wikipedia bei der Identifikation von Entitäten und deren thematischen Kontext spielen kann, zeigt das wissenschaftliche Papier Using Encyclopedic Knowledge for Named Entity Disambiguation.
Beziehungen zwischen Entitäten könnte Google u.a. über Annotationen bzw. Verlinkungen innerhalb der Wikipedia herstellen.
“An annotation is the linking of a mention to an entity. A tag is the annotation of a text with an entity which captures a topic (explicitly mentioned) in the input text.”
Mehr zum Thema Entitäten bei Google gibt es darüber hinaus in meinem Beitrag Wie erkennt Google Entitäten und wie nutzt man das für SEO? nachzulesen. Die Entwicklung eines semantischen Verständnisses bei der Deutung von Suchanfragen als auch Dokumenten hängt eng mit der Fähigkeit zusammen Entitäten sowie deren Beziehungen zu anderen Entitäten zu identifizieren und diese in ein Konzept bzw. eine Ontologie einzuordnen. Mit Hilfe von verifizierten Datenquellen wie z.B. die Wikipedia ist dies möglich. Aber für die Menge an Suchanfragen und Dokumenten, die tagtäglich neu erstellt werden ist dieses Verfahren nur bedingt geeignet. U.a. deswegen hat Google seit einigen Jahren die Entwicklung von selbst lernenden Algorithemn bzw. Machine Learning vorangetrieben.