
Durch Meilensteine wie dem Knowledge Graph, Hummingbird und Rankbrain ist Google den Schritt zu einer perfekten Suchmaschine einen gehörigen Schritt näher gekommen. Dabei spielen Statistik, semantische Theorien sowie Grundstrukturen als auch Machine Learning eine sehr wichtige Rolle. Dazu mehr in diesem Gastbeitrag von Olaf Kopp, der Teil 2 in der Artikelserie zu Semantik und Machine Learning bei Google ist.
Wer Teil 1 noch nicht gelesen hat, kann dies hier tun: Wie interpretiert Google heute Suchanfragen?

Google – semantische Suche oder doch nur statistisches Information Retrieval?
Darüber, ob Google heutzutage wirklich eine semantische Suchmaschine ist oder nicht, hatte ich mit dem geschätzten Kollegen Jens Fauldrath schon öfters anregende Diskussionen geführt.
So, wie Google für den Nutzer heutzutage Ergebnisse ausgibt, macht es den Anschein, als ob Google schon ein sehr gutes semantisches Verständnis in punkto Suchanfragen und Dokumenten besitzt. Der Weg dorthin beruht in großen Teilen auf statistischen Verfahren. Nicht auf echtem semantischen Verständnis – aber aufgrund semantischer Strukturen im Zusammenspiel mit Statistik und Machine Learning kommt Google einem semantischen Verständnis nahe.
“For instance, we find that useful semantic relationships can be automatically learned from the statistics of search queries and the corresponding results or from the accumulated evidence of Web-based text patterns and formatted tables, in both cases without needing any manually annotated data.” Quelle: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
Wie das Word2Vec-Verfahren funktioniert
Um das zu verdeutlichen, steige ich kurz in die Welt textstatistischen Verfahren ein. Google nutzt bei der Relevanzbestimmung und bei der Identifikation von Beziehungen Vektorraum-Analysen. Ein Vektorraum besteht aus einzelnen Datenpunkten, über die Vektoren im jeweiligen Vektorraum abgebildet werden können. Über den Winkel zwischen den Vektoren lassen sich Ähnlichkeiten bzw. Beziehungen zwischen den Datenpunkten feststellen. Je größer der Winkel, desto weniger Ähnlichkeit besteht. Umgekehrt gilt: Je kleiner ein Winkel, desto größer die Ähnlichkeit. Für die Hauptkomponenten-Analyse wird z.B. eine Suchanfrage als Vektor in den Vektorraum mit allen verfügbaren relevanten Dokumenten gezogen. Hierbei nutzt Google das sogenannte Word2Vec-Verfahren.
Durch die Nähe der Datenpunkte zueinander lassen sich semantische Beziehungen dieser Datenpunkte zueinander abbilden. Typischerweise werden als Vektoren Suchanfragen und Dokumente abgebildet, die so in Beziehung zueinander gesetzt werden. Ein weiterer Anwendungsfall sind Dokumente und Begriffe in diesen Dokumenten als Vektoren abzubilden, um das Konzept/Thema eines Dokuments zu identifizieren. Vorstellbar wäre aber auch, Entitäten wie z.B. Personen, Marken oder Unternehmen und Themen als Vektoren abzubilden.
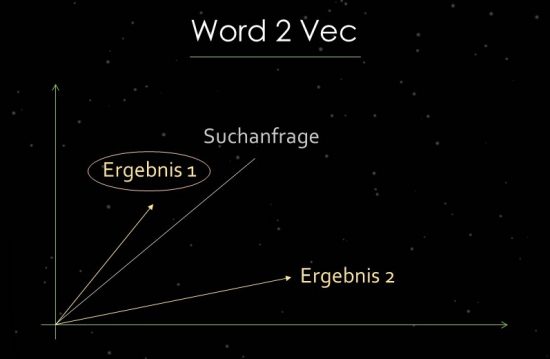
Im Beispiel erhalten Suchanfrage und mögliche Ergebnisse eine Position im Raum. Die semantische Beziehung zwische Suchanfrage und Ergebnis 1 ist größer, weil der Winkel kleiner ist. Deshalb wird Ergebnis 1 für diese Suchanfrage besser gerankt als Ergebnis 2.
Um Vektorraum-Analysen anzuwenden, müssen zuerst Dokumente indexiert werden und Konzepten bzw. Themenbereichen zugeordnet werden, welche dann in den jeweiligen themenrelevanten Korpus bilden. Ein Verfahren, um diesen Schritt durchzuführen, ist die latent semantische Analyse (LSI). Somit können Vektorräume geschaffen werden, die hinsichtlich Precision und Recall die besten Ergebnisse liefern. Über diesen Weg lässt sich auch eine semantische Klassifizierung bzw. Clustering von Begriffen durchführen, bezogen auf ein Thema.
Wer sich mehr zum Thema Vektorraum-Analysen informieren möchte, dem empfehle ich die hervorragende Präsentation des Kollegen Stefan Fischerländer.
Wie können Suchanfragen automatisch klassifiziert werden?
Das Hauptproblem in der Vergangenheit war die fehlende Skalierbarkeit u.a. bei der manuellen Klassifizierung von Suchanfragen. Dazu Ex-Google VP Marissa Mayer in einem Interview aus dem Jahr 2009:
“When people talk about semantic search and the semantic Web, they usually mean something that is very manual, with maps of various associations between words and things like that. We think you can get to a much better level of understanding through pattern-matching data, building large-scale systems. That’s how the brain works. That’s why you have all these fuzzy connections, because the brain is constantly processing lots and lots of data all the time… The problem is that language changes. Web pages change. How people express themselves changes. And all those things matter in terms of how well semantic search applies. That’s why it’s better to have an approach that’s based on machine learning and that changes, iterates and responds to the data. That’s a more robust approach. That’s not to say that semantic search has no part in search. It’s just that for us, we really prefer to focus on things that can scale. If we could come up with a semantic search solution that could scale, we would be very excited about that. For now, what we’re seeing is that a lot of our methods approximate the intelligence of semantic search but do it through other means.”
Vieles von dem, was wir als semantisches Verständnis bei der Identifikation der Bedeutung einer Suchanfrage oder eines Dokuments bei Google wahrnehmen, obliegt statistischen Methoden wie z.B. Vektorraum-Analysen bzw. textstatistischen Methoden wie z.B. TF-IDF und basiert damit nicht auf echter Semantik. Aber die Ergebnisse kommen einem semantischen Verständnis sehr nah. Gerade der vermehrte Einsatz von Machine Learning erleichtert durch noch detailliertere Analysen die semantische Interpretation von Suchanfragen und Dokumenten ungemein.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Google ist es, ein semantisches Verständnis hinsichtlich Suchtermen und indexierten Dokumenten zu erlangen, um relevantere Suchergebnisse anzuzeigen. Ein semantisches Verständnis ist gegeben, wenn man z.B. eine gestellte (Suchan-)Frage und die daran enthaltenen Terme eindeutig verstehen kann. Die eindeutige Interpretation ist oft durch Mehrdeutigkeit von Begriffen, bisher unbekannte Begrifflichkeiten, unklare Formulierungen, individuelles Verständnis etc. erschwert.
Zum besseren Verständnis können die verwendeten Wörter, deren Reihenfolge oder der thematische, zeitliche bzw. geografische Kontext beitragen. Durch Machine Learning bzw. Rankbrain ist Google nun in der Lage, über Clusteranalysen automatisch neue Klassen zu erstellen und diesen Suchanfragen zuzuordnen. Dadurch ist ein hoher Detailgrad als auch Skalierbarkeit und Performance gewährleistet. Auch die Schaffung neuer Vektorräume für Vektorraumanalysen ist besser möglich.
So führen Statistik in Kombination mit Machine Learning immer mehr zu einer semantischen Interpretation, die einem semantischen Verständnis bezogen auf Suchanfragen und Dokumenten sehr nahe kommt. Google möchte eine semantische Suche mit Hilfe von statistischen Methoden und Machine Learning „nachbauen“. Zudem baut ein zentrales Element der heutigen Google-Suchmaschine, der Knowledge Graph, auf semantischen Strukturen auf.
In Teil 3 der Artikelserie zu Semantik und Machine Learning bei Google von Olaf Kopp geht es um die Grundlagen der Semantik: Von Graphen, Entitäten und Ontologien.