
Was genau bedeutet es eigentlich, wenn Google auf Machine-Learning-Algorithmen setzt? Ich möchte in diesem Gastbeitrag klären, was genau darunter zu verstehen ist, wo diese neuronalen Netze in der Google-Suche berücksichtigt werden – und wie Webmaster und SEOs mithelfen, den Google-Algorithmen Trainingdaten zu liefern.
Dabei ist dieser Beitrag der letzte Teil meiner Artikelserie über Machine Learning. Wer Teil 1 noch nicht gelesen hat: Wie interpretiert Google heute Suchanfragen? Zu Teil 2 geht es hier: Was bedeuten Semantik und Machine Learning für die Google-Suche? Und Teil 3 ist hier abrufbar: Wie funktioniert der Knowledge Graph von Google?

Wie ich in meinem Beitrag Das semantische Web (Web 3.0) als logische Konsequenz aus dem Web 2.0 bereits erläutert habe, sind Systeme, die Informationen identifizierbar, kategorisierbar, bewertbar und je nach Kontext sortierbar machen, die einzige Möglichkeit, der Informations- und Datenflut begründend auf den Innovationen des Web 2.0 Herr zu werden.
Was ist Machine Learning?
Doch hier reicht reine Semantik nicht aus, da sie auf statischen Methoden beruht. Für semantische Systeme müssen Klassen und Labels vordefiniert sein, um Daten zu klassifizieren. Zudem ist es schwierig, ohne manuelle Hilfe neue Entitäten zu identifizieren und anzulegen. Dies war lange nur manuell bzw. in Referenz zu manuell gepflegten Datenbanken wie z.B. Wikipedia oder Wikidata möglich, was Skalierbarkeit verhindert. Deswegen benötigen die digitalen Gatekeeper immer zuverlässigere Algorithmen, um diese Aufgaben autonom zu bewerkstelligen. Hier werden zukünftig selbstlernende Algorithmen basierend auf Artificial Intelligence und Methoden des Machine Learnings eine immer wichtigere Rolle spielen. Nur so kann die Relevanz von Ergebnissen bzw. erwartungskonforme Ausgaben / Ergebnisse gewährleistet werden – und gleichzeitig Skalierbarkeit gegeben bleiben.
Bevor ich auf die Rolle von Machine Learning in der aktuellen Google-Suche eingehe, ist es wichtig zu verstehen, wie Machine Learning funktioniert. Bei der Erklärung werde ich nur an der Oberfläche kratzen, da ich selbst kein Mathematiker bzw. Informatiker bin und mir das Detailwissen zum Aufbau solcher Algorithmen fehlt.
Machine Learning ist im Themenfeld Artficial Intelligence – zu deutsch Künstliche Intelligenz – zu verorten. Der Begriff Intelligenz trifft in Bezug auf Machine Learning nicht ganz zu, da es weniger um Intelligenz, viel mehr um durch Maschinen bzw. Computer erkennbare Muster und Genauigkeit geht. Dabei befasst sich Machine Learning mit der automatisierten Entwicklung von Algorithmen, basierend auf empirischen Daten bzw. Trainings-Daten. Hierbei liegt der Fokus auf der Optimierung der Ergebnisse bzw. Verbesserung der Vorhersagen aufgrund von Lernprozessen.
Wo Machine Learning bei Google eingesetzt wird
Diese Algorithmen werden häufig so auch bei Google für die Klassifizierung, das Clustering von Informationen und daraus abzuleitende Vorhersagen genutzt. Google setzt nach eigener Aussage auf Supervised Machine Learning – was bedeutet, es an verschiedenen Stellen des Machine-Learning-Prozess Menschen vorklassifizieren und Ergebnisse evaluieren.
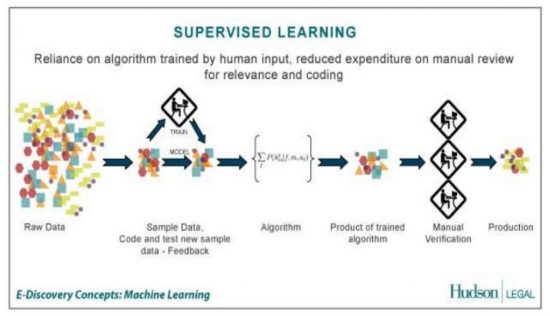
Google setzt dabei laut eigenen Angaben auf tiefe Neuronale Netze mit mindestens fünf Layern, was dann als Deep Learning bezeichnet wird. Diese Tiefe der neuronalen Netze macht es möglich, neue Modellgruppen automatisch und selbstständig zu entwerfen, was die Skalierbarkeit noch einmal deutlich erhöht.
Überall, wo Google Daten mit Labels, Kommentaren versehen muss und/oder Clustering betreiben muss, was manuell zu aufwendig wäre, kann Machine Learning zum Einsatz kommen. Offiziell ist bisher der Einsatz von Machine Learning in der Google-Suche nur bei Rankbrain bestätigt. Weiterhin kann ich mir Machine Learning aber auch beim Clustering von Dokumenten bereits im Indexierungsvorgang vorstellen. Wer mehr zu Google, AI und Machine Learning erfahren möchte, dem empfehle ich meinen Beitrag Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google mit interessanten Meinungen von geschätzten Kollegen wie Markus Hövener, Kai Spriestersbach, Marcus Tober oder Sebastian Erlhofer.
Google lernt auch dank der Mithilfe von Webmastern und SEOs
Der Aufbau einer semantischen Datenbank in Form des Knowldege Graph aber auch generell bei der Identifikation von Entitäten hängt viel von der Mithilfe von externen Personen wie z.B. Webmastern, Wikipedia-Editoren … ab. Generell möchte Google aber langfristig unabhängig an interpretierbare Daten gelangen, damit das Projekt Knowledge Graph nicht ins Stocken gerät.
Das zeigt auch das Projekt Knowledge Vault. Der Knowledge Vault wurde 2014 von Google als inaktives Entwicklungsprojekt vorgestellt, bei dem mit Hilfe von Web-Crawling und Machine Learning sowohl strukturierte als auch unstrukturierte Daten, die größte Wissens-Datenbank der Welt aufgebaut werden soll. Dazu ob und wie weit Google diese Datenbank schon aktiv nutzt gibt es bis dato keine Informationen. Ich gehe aber davon aus, dass der Knowledge Graph bereits aus dem Knowledge Vault Informationen bezieht. Mehr dazu im Beitrag Google “Knowledge Vault” To Power Future Of Search .
Ich gehe davon aus, dass Google ein großes Interesse daran hat, Informationen für den Knowledge Graph auch unabhängig von der Mithilfe externer Personen zu erkennen, am besten automatisiert. Es gibt schon einige Hinweise darauf, dass Google sich hier immer wieder durch Menschen verifizierte Trainingsdaten für die eigenen Machine-Learning-Systeme beschafft, um auch Entitäten schneller zu identifizieren und zu klassifizieren.
Zum Beispiel lässt Google auch die Informationen für die Medical Boxes von Professoren und Doktoren von Harvard sowie der Mayo Clinic gegenprüfen, bevor sie in den Knowledge-Graph-Boxen publiziert werden. Diese manuelle Prüfung könnte man auch beim Supervised Machine Learning zur Verbesserung der Algorithmen nutzen. Auch das Feedback der Such-Evaluatoren (Quality Rater) könnte Google als wertvolle Trainingsdaten den selbst Machine-Learning-Algorithmen als Futter spendieren.
Structured Data als menschliche Trainingsdaten für den Google-Algorithmus
Ein weiteres Beispiel dafür, dass Google zukünftig immer mehr versucht, unabhängig von Webmastern zu aggieren, ist das rel-Authorship-Mark-Up. Dieses Mark-Up hatte nach meiner Meinung nur eine Aufgabe für Google. Identifikation von Mustern, die für bestimmte Arten von Entitäten in diesem Fall Autoren stehen. Die Informationen und Mark-Ups wurden von Menschen (in erster Linie SEOs und Webmaster) angelegt bzw. eingepflegt und waren somit verifizierte Trainingsdaten für Google, um über die Machine-Learning-Algorithmen Modellgruppen für Autoren nach diesen Mustern anzulegen.
Damit ist es nicht verwunderlich, dass Google irgendwann die Projekte rel-Authorship oder Freebase nicht mehr weiter verfolgt hat. Freebase wurde zu Beginn von Menschen mit Daten gefüttert, die gemäß einer semantischen Grundstruktur angelegt wurden. Damit hatte Google zum Einen eine semantische Spielwiese und genug von Menschen verifizierte Trainingsdaten für die Machine-Learning-Algorithmen zur Verfügung. Freebase war aber nur kurzfristiges Mittel zum Zweck.
Wie Structured Data bei Google Shopping obsolet wurde
Nach meiner Meinung wird dies auch in den nächsten Jahren mit einem Großteil aller strukturierten Daten geschehen, sobald Google diese nicht mehr braucht. Sie sind auch nur menschlich verifizierte Trainingsdaten, die irgendwann obsolet werden könnten. Dass strukturierte Daten nur eine Zwischenstation sein könnten und Google am Liebsten auf diese Zuarbeit in Form der Auszeichnung durch Webmaster und SEOs verzichten will, zeigen auch neueste Entwicklungen bei Google AdWords bzw. Google Shopping.
So bekamen AdWords-Werbetreibende, die einen Shopping-Feed betreiben in den letzten Monaten eine Mail mit folgendem Wortlaut:
„Ab dem 30. Oktober 2017 werden die aktuellsten Informationen zu Preisen und Verfügbarkeit Ihrer Artikel anhand von Anmerkungen für strukturierte Daten oder zusätzlichen Informationen (wenn keine strukturierten Daten verfügbar sind) ermittelt. Somit profitieren Ihre Kunden von einer höheren Nutzerfreundlichkeit bei Google Shopping.“
Wenn man sich dazu mal die Shopping Hilfe ansieht findet man dort folgende Formulierung in Bezug auf die Shopping-Feeds:
„Advanced extractors are able to find price and availability information on a product’s landing page. They use a combination of statistical models and machine learning to detect and extract product data from your website independent structured data markup. “ Quelle: https://support.google.com/merchants/answer/3246284?hl=en
Google hat also über die letzten Jahre durch Machine Learning gelernt, automatisiert und unabhängig von strukturierten Daten Inhalte zu interpretieren und einer Klasse zuzuordnen. Dabei waren die Shop-Betreiber, die in den letzten Jahren brav ihre Shopping Feeds mit strukturierten Daten ausgezeichnet haben, eine wichtige Hilfe – ein verifiziertes Trainingsfutter für den hungrigen Machine-Learning-Algo von Google Shopping.
Auch aus dem Mund von Gary Illyes wird dieses Ziel von Google klar geäußert:
“I want to live in a world where schema is not that important, but currently, we need it. If a team at Google recommends it, you probably should make use of it, as schema helps us understand the content on the page, and it is used in certain search features (but not in rankings algorithms)… Google should have algorithms that can figure out things without needing schema…” Quelle: https://searchengineland.com/gary-illyes-ask-anything-smx-east-285706
Ich muss dazu erwähnen, dass Gary in der selben Quelle die Frage, ob schema.org-Daten als Trainingsdaten genutzt werden verneint. Das spricht gegen meine Vermutung.
„ No, it’s being used for rich snippets.”
Fazit: Machine Learning war ein notwendiger Schritt hin zu einem annähernd semantischen Verständnis
- Google wollte mit dem Knowledge Graph und dem Hummingbird Algorithmus die semantische Suche einführen. Heute wird aber klar, dass das Ziel, ein semantisches Verständnis zu entwickeln, lange an der fehlenden Skalierbarkeit gescheitert ist.
- Erst im Zusammenspiel mit Machine-Learning-Systemen wird die semantische Klassifizierung von Informationen, Dokumenten und Suchanfragen in der breiten Masse an Suchanfragen und Dokumenten praxistauglich, ohne große Abstriche in der Performance machen zu müssen – auch Dank tatkräftiger Mithilfe der SEOs und Webmaster, die Informationen selbst manuell auszeichnen.
- Auch die Fähigkeit, Voraussagen zu treffen, was ein Nutzer möchte, wenn er einen bisher unbekannten Suchbegriff in den Suchschlitz eingibt, ist erst durch Machine Learning möglich.